
A brief introduction to explainable AI

Artificial intelligence is a revolutionary technology that is disrupting the way we work, live, and interact with each other. However, the increasing complexity of AI systems makes them opaque and hard to reason about. Traditionally, it was enough for AI practitioners to test the reliability of machine learning models by building evaluation datasets, defining some metrics, and computing those metrics over the evaluation sets. However, many users don’t simply trust these metrics, and need a deeper insight on how the models are computing the results. This is how the field of explainable AI or XAI was born.
In this post we will introduce the concept of explainable AI, show different types of explainable AI, and describe some popular algorithms such as Grad-CAM, LIME or SHAP.
What is explainable AI?
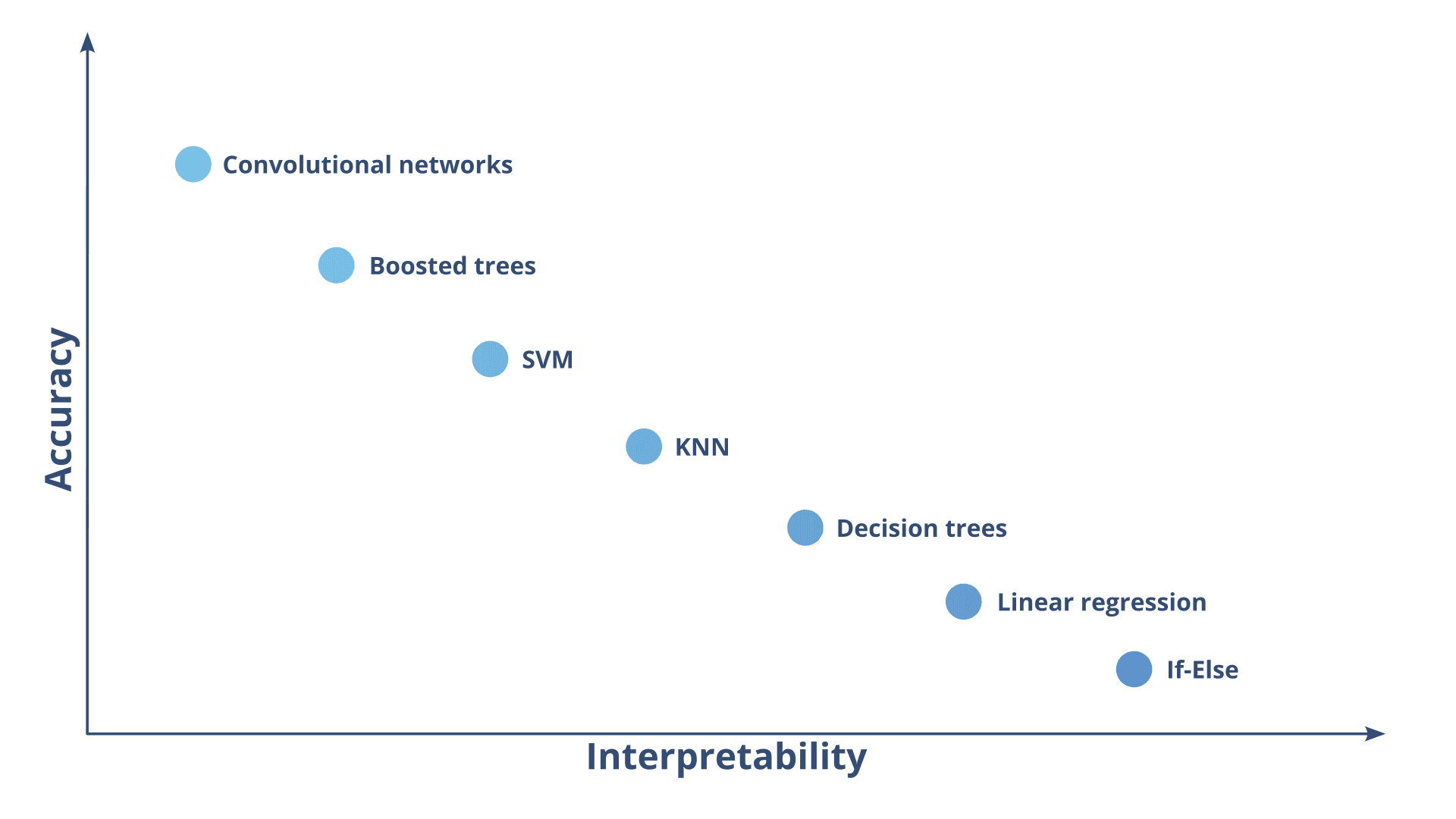
Explainable AI, or XAI, is an umbrella term for a set of methods that try to show explicitly why a machine learning model is producing specific results. As AI algorithms become more powerful, they also become more opaque. This opacity is what led researchers to coin the term “black-box”, referring to models where it is hard to understand why they came up with certain results. Figure 1 shows a chart illustrating the typical accuracy-interpretability tradeoff.
Black-box models are hard to apply in some fields, like medicine or finance, where human oversight is often required. However, for this oversight to be effective, users should have tools to verify the model’s outputs. Users should be able to see why a loan was approved or why a treatment was selected. This is one of the main reasons why the field of explainable AI gained popularity after the rise of black-box deep learning models.
However, the term “explainable AI” does not only apply to black box models, as it is a broad field without a fully consolidated scope. For instance, the term “explainable” is often associated with post-processing algorithms that analyze a black-box model. While, on the other hand, an “interpretable” model usually means that the model itself can provide some sort of explanation.
Thanks to explainable AI algorithms, we can find hidden biases in the way models operate and better characterize their outputs. Explainable AI algorithms are a fundamental tool for organizations who suspect that a model may be computing misleading predictions, and want to build confidence before pushing it to a production environment.
Why does explainable AI matter?
Explainability and interpretability is crucial in AI because it allows humans to understand and trust the decisions made by intelligent systems. Without proper understanding, users will often mistrust, or even fear AI.
In some critical applications of AI, such as credit scoring in the U.S., explainability is not only important, but necessary. Creditors are required to notify customers of the specific reasons for denying a credit application. Another example is the use of personal information to perform automatic inferences in Europe; here, users have the right to get an explanation of the decision reached using automated systems that use personal information and produce effects that significantly affect them.
While regulatory requirements are a good reason to pursue AI explainability, they are not the only good reason. For instance, an AI model may recommend a treatment plan for a patient, and the doctor may not agree with that plan. At first sight, this may look like an error in the machine learning model, however, if we include some sort of explanation for why the model is recommending that treatment plan, the doctor may be able to identify some variable he overlooked and finally agree with the model.
Explainability also helps identify and address biases in AI systems. If an AI system is making decisions based on biased data or algorithms, explainability can help identify where those biases are coming from and how to address them. This is important because biased AI can perpetuate and even amplify existing inequalities.
Explainable AI taxonomy
AI explainability is a somewhat vague term that is used to group different techniques aimed at increasing the trust users have on machine learning models. In order to better understand the wide spectrum of the explainable AI field, this section will show the different types of AI explainability techniques. These techniques will be categorized following four different criteria: 1) Intrinsic or post hoc. 2) Model specific or agnostic. 3) Local or global explanation. 4) Explanation results.
Intrinsic or post hoc
Some machine learning models have intrinsic properties that make them interpretable. Two popular examples are linear models and decision trees. Each of the feature weights in a linear model can be interpreted as the importance of that feature. On the other hand, the average information gain for all the nodes using a specific feature in a decision tree, can be used as a feature importance indicator.
However, most machine learning models do not have an explicit way of indicating the importance of each feature. For these models, we need to use a separate algorithm that computes explanations based on the way the model behaves.
Model-specific or agnostic
Some explainability techniques can be applied to any machine learning model, whereas others can only be applied to specific models.
A popular example of model-specific explainability algorithms is Grad-CAM, which uses the activation maps of convolutional layers to provide visual explanations. If a model doesn’t have convolutional layers, or the convolutional network does not have a specific structure, Grad-CAM can’t be applied effectively.
On the other hand, algorithms such as LIME or SHAP can be applied to any machine learning model. These algorithms treat the machine learning model as a black box, and play with the input samples and model results to compute explanations.
Sample or model centered
Some explainability techniques are aimed at identifying why the model computed a specific result for a sample. For instance, Grad-CAM computes activation maps for a specific sample after running this sample through the convolutional network.
On the other hand, other explainability techniques try to explain how the model operates in general. SHAP is a good example of this approach, which tries to determine the importance of each feature using Shapley values.
Explanation results
Explainability techniques produce different sorts of explanations. Some techniques compute feature summaries, such as a single number for each feature indicating its importance. Other techniques rely on extracting the internal information of specific models, such as the feature weights of a linear model. Another popular example is to use a simpler, interpretable, model to approximate the results of the black-box model; these simpler models are usually called surrogates.
Examples of explainable AI
We have already seen the wide variety of explainable AI techniques, however, during the last years a few algorithms have stood out. Methods such as SHAP have gained a lot of traction thanks to their applicability, whereas traditional interpretability techniques such as inspecting decision trees have stood the test of time. In this section we will give a brief introduction to some popular explainable AI algorithms.
Decision trees
Decision trees are a popular machine learning model for non-linear data. Tree models split the data iteratively in a tree-like structure. In this tree, each node represents a decision where a cutoff value for a certain feature splits a set of samples into two subgroups. The selected feature and cutoff value for each node is chosen to maximize the information gain between this node and its children. Specifically, we compute the entropy of the parent, and child nodes, weighted by how many samples reached them, and try to maximize the entropy gain using the following equation.
The good thing about this approach is that we can use this information gain as an indicator of the feature importance. However, depending on how we build the tree, the same feature may be used more than once. Because of this, when computing the importance of a certain feature, we have to check all nodes using this feature and weight the information gain of each node using the fraction of samples that reached it.
Grad-CAM
The topic of explainability started gaining importance with the rise of convolutional networks. These convolutional networks are capable of achieving astounding results, however, with this increased capability, comes an increased model opacity. To help users debug convolutional networks, the Gradient-weighted Class Activation Maps (Grad-CAM) method was created.
Grad-CAM produces visual explanations from any convolutional classification model. In summary, this method has the following steps: 1) Find the last convolutional layer of the model you want to inspect. 2) Run an image through the convolutional network to get a prediction. 3) Get the activations of the last convolutional layer. 4) Get the gradients of the model output with regard to the last convolutional layer. 5) Average the gradients so that we have one value for each convolutional filter. 6) Sum the last convolutional activations weighted by averaged gradients.
The intuitive explanation is that the last convolutional layer should highlight the areas of the image that are important for the output of the model. Also, when a specific filter of the last convolutional layer changes a bit, but the output of the model changes a lot, this means that this specific filter is important for the model output; in other words, the gradient of the output with respect to this filter is large. This way, we can “select” the activations of the last convolutional filter using this gradient information. Figure 2 shows an example Grad-CAM visualization.

LIME
Another popular algorithm to generate explanations is LIME, or Local Interpretable Model-agnostic Explanations. LIME is a model-agnostic algorithm, meaning that it does not impose specific requirements on the model it explains. This is different from Grad-CAM, which required the model to have one last convolutional layer just before computing the final outputs.
LIME works by generating random samples around the sample we want explanations for, and checking how the model behaves on these new random samples. The “Local Interpretable” part of LIME means that it will try to build an interpretable model, such as a linear regression model, using these local samples. For instance, in the case of images, LIME starts by dividing the input image in superpixels, and generates variations of this image by randomly turning off some superpixels. Then, LIME builds a linear model fitting the presence or absence of these superpixels to the output of the black box model, and generates superpixel visualizations based on the fitted linear coefficients. Figure 3 shows a LIME explanation.

SHAP
While LIME is usually targeted at getting local explanations for specific samples, SHAP is better suited to compute both global and local explanations.
SHAP is an explainable AI algorithm inspired by Shapley values, a game theory method that tries to distribute the “payout” between different players. These players can be interpreted as features, in the context of machine learning algorithms.
The general idea is to compare the output of the model for a given sample, and the same sample with a feature withheld. This is evaluated for all feature combinations, in order to take into account how different features “cooperate” to achieve specific results. Finally, the feature contributions across all combinations are averaged, and we end up with the contribution of each feature for a specific result. This process is summarized in the following equation.
The problem with SHAP is that it samples every possible feature combination. If a model only operates using 4 features, SHAP only has to sample 64 coalitions. However, with just 30 features we would have to evaluate the model on millions of samples. Because of this, the authors have created specific versions such as KernelSHAP or TreeSHAP that try to minimize the computational burden.
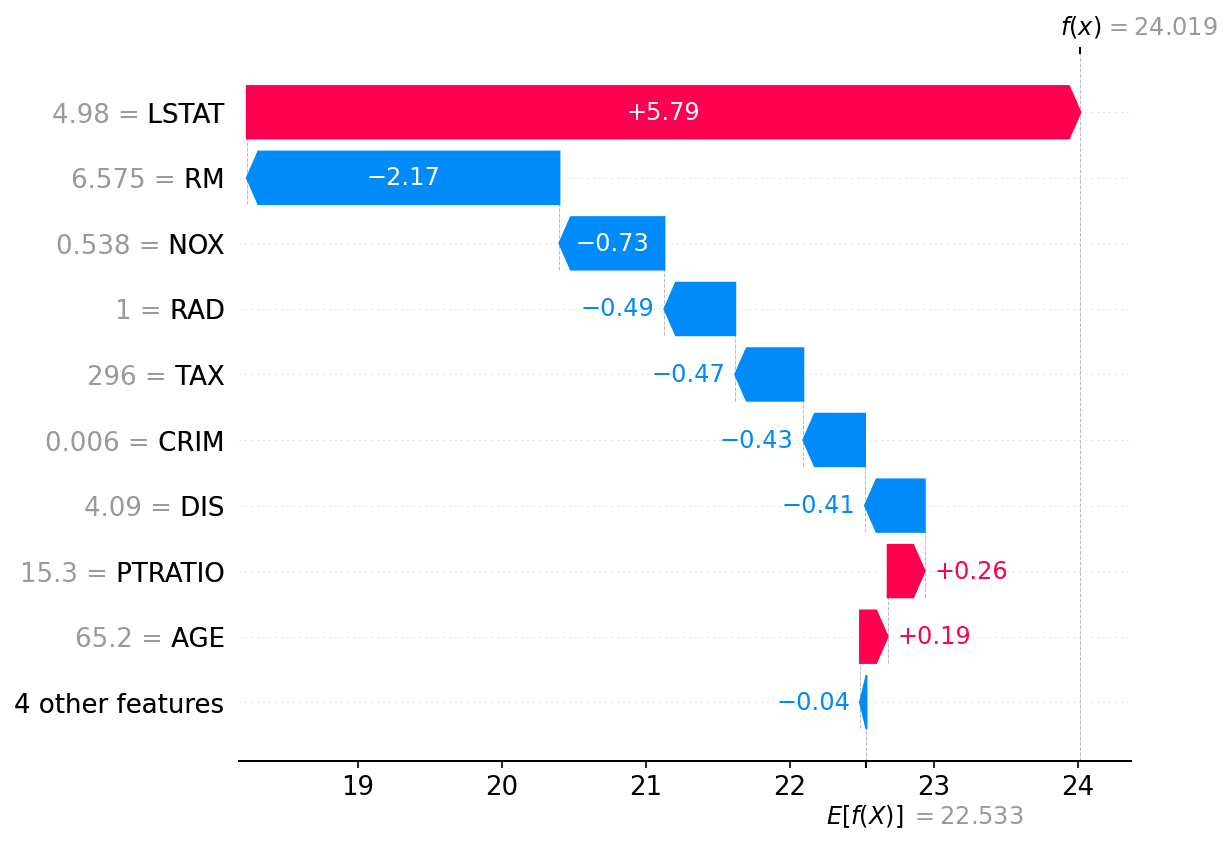
KernelSHAP is still a model agnostic approximation, but it uses a linear model to approximate a subset of all possible coalitions. This approach is quite similar to LIME, however, the contribution of each sample is weighted differently. In LIME, the weight was computed according to the distance between the target sample, and the newly generated sample. In SHAP, the weight is computed according to the number of features used. In fact, according to the authors “If you use the Shapley kernel we proposed as LIME's local kernel then the linear LIME method will produce estimates of SHAP values”. The following figure shows the result of explaining a XGBoost regressor trained on the Boston dataset.
Conclusion
Explainable AI is an increasingly critical aspect of the machine learning lifecycle. As AI continues to play an ever-growing role in our lives, it is essential that we can understand the decisions made by these systems. By making AI models more transparent and interpretable, we can increase trust in their decisions and help ensure that they are making fair and ethical choices.
In this post we gave an overview of AI explainability, introducing the concept of model explainability, presenting a wide overview of the AI explainability landscape, and showing specific examples of commonly used techniques.
As AI continues to become more pervasive in society, it is clear that explainability will become a critical factor. By prioritizing AI explainability, we can build trustworthy systems that help us make reliable decisions.
