
What is generative AI and how do AI writers and image generators work?

Generative AI is a rapidly growing field of artificial intelligence that aims to create new content, such as images, text, and music. This technology has the potential to revolutionize the way we create and consume content, and it is already being used in several industries, including the arts, entertainment, and marketing.
In this blog post, we will explore the different ways that generative AI is being used to create new content across different domains. We will put special focus on the two most popular modalities of generative AI: AI for writing text, and AI for generating images. We will also explain briefly but technically the main generative AI systems that power these modalities, such as ChatGPT and Stable Diffusion.
Many users have started interacting with generative AI models through web apps, but they may not fully understand what these models are and how they work. This post will address this gap and help you to learn more about the field of generative AI and the main techniques being used.
What is generative AI?
Before diving into generative AI, we should first understand the general concept of AI. Some researchers don't tend to like the word AI, as it often is used to overhype machine learning. In fact, most AI we see today is actually machine learning so, what is machine learning? Machine learning is just a way of teaching computers to generate outputs using samples. These samples are usually text, images, or audio, and the outputs are usually a label, a numerical value, or another image, text, or audio. Once trained, these algorithms can analyze new samples, previously unseen, with impressive accuracy.
Generative AI is a subset of machine learning that aims to generate new content, such as audio, images, or text. Generative AI models use specialized architectures, such as transformer networks, generative adversarial networks, or encoder-decoder networks, that can learn from training data and produce realistic and novel creations that reflect the characteristics of the data without fully replicating it.
Generative AI brings huge potential for content creation, as it can streamline the creative process, specially in the drafting stages. Whether it is a social media post, an image for a blog post, or background music, generative AI can help you create quick and high quality drafts that will make your work easier.
Generative artificial intelligence for text generation
Text based AI applications like GhatGPT have become very popular lately. However, before them, text classifiers were the dominant type of text AI for over a decade. Text classifiers assign a category to a piece of text, something like “positive review” or “negative review”. These models are really useful, since they can streamline tasks such as customer support, where the model can automatically categorize complaints based on the team that needs to address them.
However, in the last few years a new trend has emerged, while previous models could just classify text, general purpose AI text generators capable of following simple instructions have become more popular. These instruction following models are self-supervised at their core, which means that they do not rely on human-labeled data, but instead create their own labels from the data itself. This reduces the need for manually labeling training data, which facilitates the use of ever larger datasets. This way, they can learn from large amounts of unlabeled text data, such as web pages, books, news articles, and more.
By processing huge amounts of data, self-supervised methods can build knowledge and help us complete common tasks such as answering questions. However, even though self supervised algorithms are capable of amassing a large amount of knowledge, they usually need to be fine tuned to achieve the level of interactivity of applications like ChatGPT, Bing Chat, or Bard.

ChatGPT
ChatGPT is a chatbot capable of very human-seeming interactions. It was launched by OpenAI in late 2022 and became wildly popular overnight. The main reason for the success of ChatGPT was its ability to generate coherent and engaging responses to natural language requests; you just write your instruction, and ChatGPT will provide an answer. Moreover, you can use ChatGPT for free using Bing chat
ChatGPT is powered by a transformer network, a type of machine learning model that has become very popular since 2017. Transformer networks are very good at natural language processing tasks, such as text summarization, machine translation, or question answering. These networks use a mechanism called attention, which allows them to learn how words in a sequence relate to each other. This makes them suitable for NLP tasks where the meaning of a sentence depends on the context of the words around it.
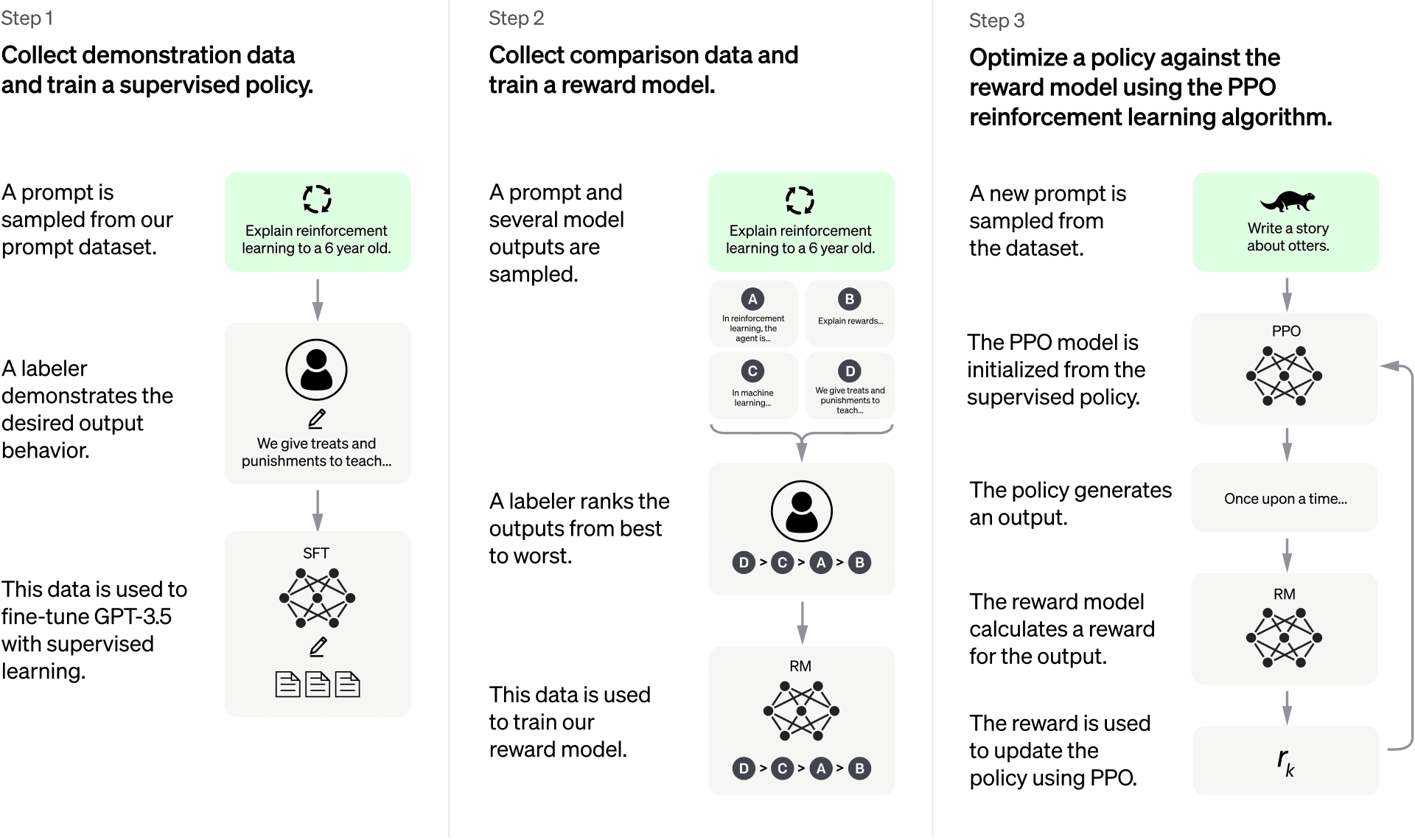
However, the language modeling capabilities of transformer networks are not enough to train a general purpose chatbot. Models like ChatGPT are usually trained using a multi-step approach. Specifically, this chatbot was first trained for language completion in a self-supervised way, then trained with manual prompt - answer pairs, and then refined using reinforcement learning.
Following this approach, the first step is to build a language model capable of completing sentences. This is achieved by training the transformer network in a self-supervised way, feeding the model a large corpus of books, blogs, and other information found on the internet. The result of the pretraining phase is a large language model (LLM), often known as a pretrained model.
Right now, this pretrained model is very good at completing sentences, but not that good at following instructions. When asked “Write a poem” it may reply “ said the poet”, this is because narrative passages are more frequent on the internet than instruction-answer sequences. In order to overcome this limitation, the pre-trained LLM is fine tuned on a set of instruction - answer pairs that are manually crafted. In this step, also called behavior cloning, the internal knowledge representation of the LLM is slightly adjusted so it's more likely to reply to instructions rather than just completing sentences.
Finally, once the LLM has been fine-tuned using manually crafted instruction - answer pairs, it usually undergoes one last refinement step. In this last step, the model is fine tuned using reinforcement learning, a type of training that allows machine learning models to learn by allowing them to generate full responses, and grading them using a reward model. This reward model is in itself another machine learning model, trained to rank different replies to a prompt and, by using this reward model, the model can improve its performance a little bit more. One prompt may have several good answers, but some of them may be better than others, and this step prioritizes just that: selecting the best answer among the possible ones. Also, it is true that different people may have different opinions on how to rank responses, this may be the reason why ChatGPT, shows a thumbs up/down button next to each reply; this way, the app can gather data on the preferences of its users.
Generative artificial intelligence for creating images
Text-to-image AI art generators are a special kind of AI that can produce images from natural language descriptions. Although these models have not received as much attention as ChatGPT, online apps for generating images have mushroomed over the last few years and there are now dozens of nice options capable of generating stunning artworks.
In reality, AI powered image generators have been around for quite some time now. However, as in the case of AI models for language understanding, these older models were not as powerful as the ones we now have. Two good examples of older AI for image generation are GANs, and the neural style transfer technique.
GANs, or Generative Adversarial Networks, which were introduced in 2014 in the paper “Generative Adversarial Networks”, work by putting two neural networks to compete against each other. One network, the generator, tries to create new images that are indistinguishable from real images. The other network, the discriminator, tries to distinguish between real images and fake images created by the generator. These two networks are trained together until a stalemate is achieved, meaning that the generator can fool the discriminator half the time. By doing this, we can train an image generator that can, at least, fool AI image classifiers, although the results can sometimes be far from perfect.
Another example of older AI for generating images is the Neural Style Transfer technique. Introduced in 2016, this technique can create new images that mimic one specific style, while preserving the content of the photos we choose. For example, if we have a photo of a city and a painting by Van Gogh, we can use Neural Style Transfer to create a new image that has the same buildings and streets as the photo, but with the brush strokes and colors of Van Gogh’s style. This technique works by feeding the style and reference image to a pretrained network, and iteratively tweaking the reference image so that the style neural activations are closer to those of the style image.
However, none of these techniques could match the complexity of modern AI generators such as Midjnourney or, as a free alternative, Stable Diffusion. These new models are trained on massive datasets of text-image pairs, which allows them to create much more realistic and detailed images.

Stable Diffusion
One of the most popular generative AI image creation tools is Stable Diffusion. Stable Diffusion is a model that can be easily deployed using apps like Web UI, which allows users to generate images by providing simple text prompts. For example, you could enter the text prompt "A cat sitting on a fence" and the Stable Diffusion Web UI will show an image of a cat sitting on a fence generated by the AI model.
Stable Diffusion, contrary to ChatGPT, is an open source model and this allows us to get a deep understanding of its inner workings. This AI model is based on a technique called latent diffusion, which involves adding and removing noise from images in a controlled way. The model learns to create realistic images by reversing the process of adding noise, starting from random noise and gradually removing it until it reaches the desired image.
This reverse diffusion process, iteratively removing noise from a random image, is achieved using a U-Net architecture. U-Net is one specific kind of convolutional network that was originally designed to segment biomedical images, but is also capable of generating RGB images. This network is usually trained in a supervised manner, with image-image pairs which, in this case, will be the noisy image and the noise that we want to remove at the current reverse diffusion step. When training the model, the U-Net learns to predict the noise we are adding at each diffusion step; then, during inference, the noise predictions generated by the U-Net can be used to reverse the diffusion process, subtracting the noise from the image and then recovering a denoised image from random noise.
However, using the U-Net directly to process images directly would quickly turn prohibitively expensive for moderate to large images. If we look at the original U-Net paper, the authors used images of 512x512 pixels to reduce the memory footprint of the model, but that kind of images would already be prohibitively expensive for Stable Diffusion which has additional layers around the U-Net. Instead of working directly with the image pixels, Stable Diffusion works in a latent space, a compressed representation that stores the information of the processed image in a smaller amount of “pixels”. This is achieved by using a variational autoencoder, a kind of encoder-decoder network that is trained to output the same image it was fed. Once trained, we can feed an image to the variational autoencoder, and use the internal activations of the network as a compressed representation of the image. If we just save the feature block that lies between the encoder and decoder, we can perform the reverse diffusion on that and save a huge amount of computational resources.
Even with all this processing, the model isn't capable of following text prompts yet, we still need to condition the reverse diffusion process. To achieve this, cross attention layers are added to both the encoder and decoder sections of the U-Net model. These cross attention layers work similarly to the self-attention mechanism used by ChatGPT, but take into account both the text information of the prompt, and the visual information of the diffuser. This way, the activations of each layer of the original U-Net architecture are projected using the text prompt.
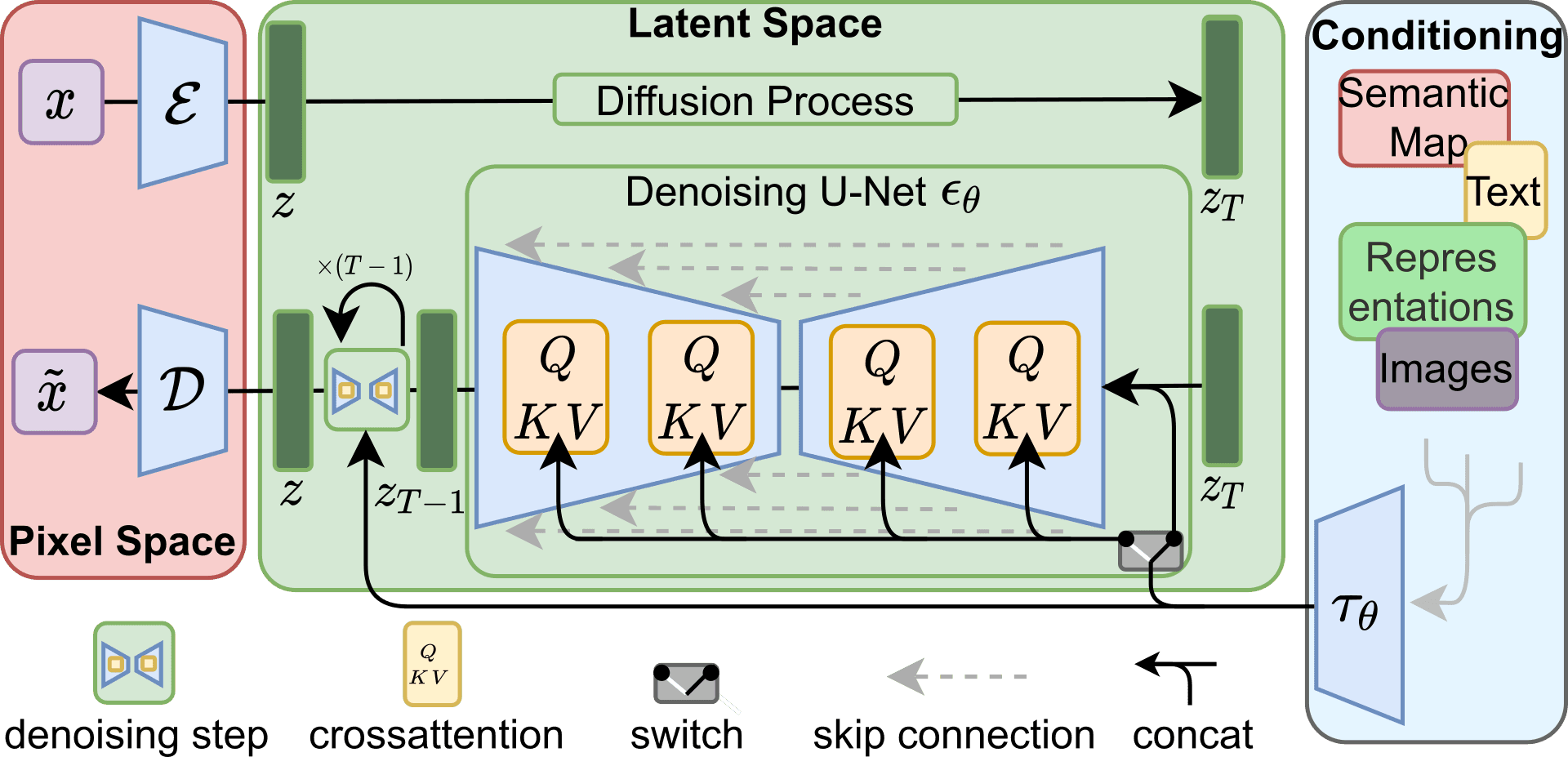
If we put together these three components: the U-Net, the variational autoencoder, and the cross attention layers, we get a model that can generate high quality images following text prompts.
Conclusion
Generative AI is a game-changer technology with the promise to revolutionize content creation. This kind of AI can produce amazing and original content across different domains, such as images, text, or music, and people are already taking advantage of its capabilities through apps like ChatGPT or Stable Diffusion Web UI. In this blog post, we have introduced the concept of generative AI, and explored the main apps people are using to take advantage of this technology: Stable Diffusion for image generation, and ChatGPT for writing text.
As this technology continues to develop, we can expect to see even more amazing and creative applications in the years to come. For now, the cover photo for this post was created using Stable Diffusion. Additionally, these models are helping creative jobs like marketers write catchy headlines, slogans, or descriptions.
We hope that this blog post has given you an overview of the different ways that generative AI is being used to create new and innovative content across different domains. If you are interested in learning more about generative AI models and how they can help you with your projects, feel free to contact us using the contact page or the chat button.
