
How does face recognition work?

Face recognition is one of those technologies that have been around for a couple of decades now, but has been heavily revolutionized by recent developments in AI. From automated tagging in social networks, to securing access to our smartphones, face recognition is playing an increasingly important role in our daily lives. However, its inner workings remain a mystery to the general population.
In this blog post, we'll describe how face recognition works, showing specific methods that are commonly used in the industry. We'll also delve into some of the ethical concerns surrounding this technology, such as privacy violations and bias. By the end of this post, you'll have a better understanding of what face recognition is, how it works, and what specific techniques are commonly used in a face recognition system.
Typical steps in a face recognition pipeline
A face recognition system uses machine learning algorithms to detect faces and match them against a database of previously recorded faces. Depending on the size of this database, we can be talking about face verification, or fully fledged face recognition.
Face verification is the process of comparing two face images to determine if they both show the same person. This one-to-one matching is often used in access control applications such as Face ID. On the other hand, face recognition is the process of identifying one individual from a large database. Face recognition systems are typically more complex than verification systems, since they require robust image processing algorithms and scalable architectures. Face recognition systems may have to account for variable lighting, angles, and different environmental factors. Additionally, they often require a sophisticated architecture to accurately match individuals across a potentially huge database.
Like similar AI-powered image recognition methods these systems have two kinds of errors: false positives, and false negatives. When the face recognition software matches a person's face to a database entry that does not correspond, we are talking about a false positive error. On the other hand, when the face recognition system fails to match someone's face, but that person is registered in the database, we are talking about a false negative error. The relation between false positives, and false negatives is usually a trade off, and researchers have to fine tune the system to balance them depending on the final application. For example, if you are using face recognition to unlock your phone, you may prefer to try a few times rather than allowing other people to use your phone; this means that you want the face recognition system to have a higher false negative than false positive rate.
Nowadays, there are different face recognition libraries such as Deepface that implement a complete analysis pipeline. This recognition pipeline consists of four stages: Detection, alignment, representation, and verification.
Face detection
Face detection is the first step in a face recognition pipeline. It involves identifying the presence of faces in an image and locating them, usually by computing a set of bounding boxes. This is typically achieved using machine learning models that analyze image features such as color, texture, and shape using a set of complex analysis blocks learned from a training dataset.
A popular family of face detection algorithms is single stage convolutional detectors. These convolutional networks analyze the image in just one pass, without relying on intermediate steps such as proposal generation, achieving fast detection speeds. Some popular architectures typically used in face detection are RetinaFace, SSD, or YOLO. Figure 1 shows the result of using the RetinaFace algorithm to detect faces.

Face alignment
Once detected, a face may be slightly rotated, which can reduce the performance of the face recognition pipeline. In order to achieve the best accuracy possible, a face alignment step is usually introduced. This face alignment procedure involves identifying facial landmarks such as the eyes, nose, or mouth, and then transforming the face image so that the position of these landmarks is standardized.
Some face detection algorithms such as RetinaFace compute the necessary landmark locations to perform face alignment. Specifically, RetinaFace detects both eyes, the nose, and the edges of the mouth. Once detected, we can rotate the image so that both eyes are at the same height. On the other hand, many face detection algorithms don’t explicitly compute any landmark locations. In this case, users can introduce a post-processing step that uses another lightweight network, such as a MobileNet, to regress some landmarks.
Face representation
Face recognition systems don’t usually rely on the raw face images to perform recognition, instead, they first compute a digital fingerprint of the face. This fingerprint is just a, relatively small, list of numbers that summarize the appearance of the face. Face recognition systems store these lists, also called feature vectors, in large databases that can be queried to find similar faces.
Traditional methods such as LBPH, or Local Binary Pattern Histograms, use simple techniques such as thresholding and histograms to represent the face image. However, with the rise of deep learning these simpler algorithms have become less popular. Nowadays, state of the art face recognition systems use convolutional networks such as ResNet, or vision transformers such as ViT, trained using softmax-based loss functions such as ArcFace.
Face verification
Once the feature vector that describes a face is computed, a face verification step finds the closest face descriptor in a database and checks if they are similar enough. Traditionally, this is achieved by computing a distance metric between the target vector and each face descriptor in the database. However, this can be prohibitively expensive, so faster methods such as ANN or Approximate Nearest Neighbors are used for databases with millions of individual face descriptors.
Regardless of the approach, a distance metric is commonly used to compare the target, and registered face descriptors. There are several distance metrics including euclidean distance, cosine distance, or Mahalanobis distance. One of the most simple, the euclidean distance, calculates the distance between two vectors as the square root of the sum of the squared differences between their elements.
Popular face recognition algorithms
We have already seen the typical steps in a face recognition pipeline. From Haar cascades to deep neural networks, face recognition can be implemented using a wide range of algorithms. In this section we will describe two popular algorithms in a face recognition pipeline: RetinaFace and ArcFace. These algorithms leverage the power of deep networks to provide robust and reliable face detection and recognition, enabling face recognition in real world scenarios such as access control.
RetinaFace
RetinaFace is a popular face detection algorithm that follows a convolutional architecture to locate faces in images. The main characteristics of RetinaFace are: 1) Using a single stage to perform detection. 2) Computing multi-scale information using a feature pyramid network. 3) Taking advantage of a context module to enlarge the receptive field used to perform a detection. 4) Learning different tasks at the same time to improve the face detection performance. Figure 2 describes the RetinaFace architecture.
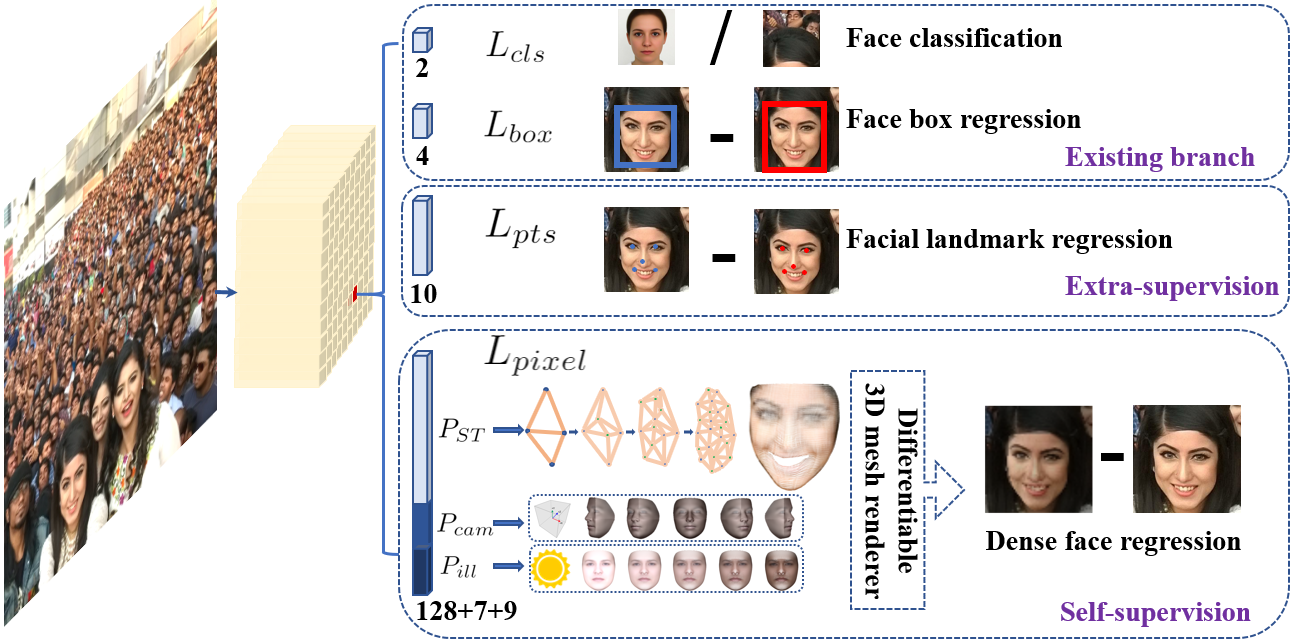
One desirable trait of every face detector is inference speed. In order to maximize this speed, RetinaFace follows a single-stage approach to perform detection. Unlike proposal-refinement networks, RetinaFace extracts information directly from the early convolutional layers of a classification network like ResNet. This information is used to compute the face anchors using a convolutional detection module.
Another key feature of RetinaFace is the use of a feature pyramid network to extract multi-scale features. Detecting faces at different scales is a basic feature of every detector, however, instead of creating an image pyramid and analyzing each scaled image independently, RetinaFace builds a feature pyramid. This feature pyramid adds strong visual information to every intermediate output of a convolutional network to improve the trade-off between scale, and semantic information.
Additionally, in order to maximize the detection robustness, RetinaFace includes a context module to enlarge the effective receptive field used in each detection. By performing multiple sequential convolutions before the detection module, RetinaNet increases the effective receptive field used to compute the bounding boxes.
Finally, RetinaFace also takes advantage of multi-task learning to improve the face detection performance. Instead of just computing the bounding boxes, RetinaNet has four different outputs. The main two outputs are the face bounding boxes, and the face score. However, RetinaFace is also trained to locate 5 facial landmarks, and to recreate the appearance of the located face. This approach allows the algorithm to learn shared representations, improving the robustness of the learned features and, in turn, increasing the face detection performance. Additionally, the regressed face landmarks can be used to align the face patch so that the recognition performance is optimal.
ArcFace
ArcFace is a face recognition algorithm that uses a deep convolutional neural network to generate highly discriminative face descriptors. Specifically, ArcFace is a loss function engineered to improve the performance of face identity classifiers by enhancing the separation between different face identities in the feature space. The main idea is to train a classification network, such as a ResNet, to classify the identity of each face while having a margin between each identity embedding.
The ArcFace loss is based on the softmax loss, which is commonly used in many deep learning applications, specially in classification applications. However, unlike the softmax loss, which encourages the features of each class to be well separated from each other in the feature space, the ArcFace loss additionally enforces an angular margin between the features of different classes.
This is achieved by modifying how the softmax loss is computed. The softmax loss receives the result of dot multiplying each weight and intermediate variable vectors. Instead of just performing this multiplication, the dot product is rewritten as multiplying the magnitude of both vector times its cosine. Now, if we add a margin to the angle of the specific class we are targeting when computing the loss, the vectors of this class should be separated from the rest by the desired margin. Figure 3 shows how different loss functions enforce different decision margins.
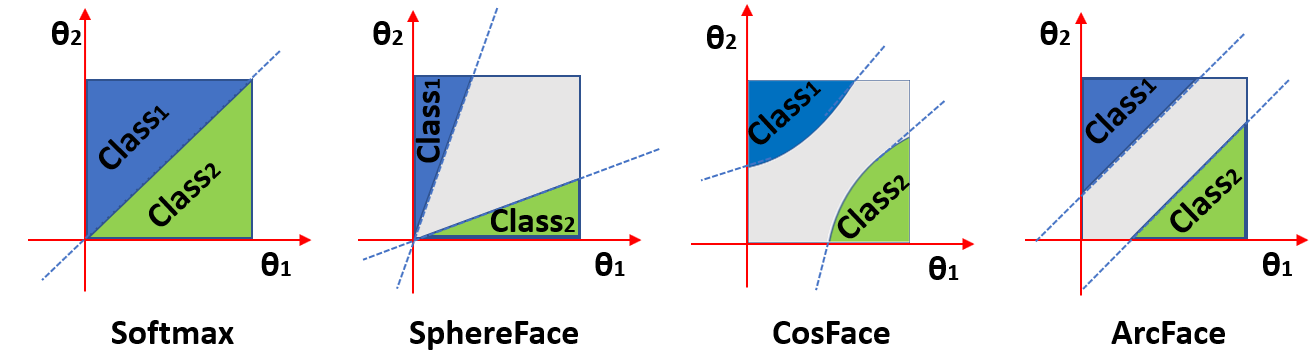
By introducing the angular margin, the ArcFace loss effectively pulls the features of the same class closer together and pushes the features of different classes farther apart, resulting in a more discriminative feature space that improves the accuracy of face recognition. Additionally, the margin can be adjusted to control the degree of inter-class separability, allowing the algorithm to adapt to different levels of classification difficulty.
Scaling face recognition applications
We have described a face recognition pipeline using RetinaFace for face detection and alignment, and a convolutional classifier trained using ArcFace for face representation. However, as face recognition systems become more prevalent, the need for scalable architectures that can handle large volumes of transactions in real-time becomes increasingly important. Designing a real-world face recognition system requires more than simply deploying a couple of convolutional networks, we need to optimize specific requirements such as latency, throughput, or memory usage. In this section, we will address some key aspects of scaling face recognition applications. First, we address the need to run the face detection and representation networks in real time. Second, we show some strategies to handle training and inference when dealing with millions of face identities.
First things first, how can we scale the detection and representation steps? Well, the main issue with these steps is processing speed, so we can take advantage of cluster technologies such as Kubernetes, Ray, or your cloud provider autoscaler to scale inference workers horizontally. Cluster frameworks such as Kubernetes have gained a lot of popularity for making deployments highly scalable, available, and portable across different infrastructures. However, while Kubernetes is certainly quite powerful it is also resource-intensive and complex to set up and manage. On the other hand, frameworks like Ray have been specifically designed to simplify scaling machine learning workloads. Creating a Ray cluster is as simple as creating a 50-100 line YAML file describing the workers. Ray does not require you to explicitly create deployments, services, or configmaps like Kubernetes, you just define your worker requirements and that's it. Additionally, we can decorate our inference code with
@serve.deployment(ray_actor_options={"num_cpus": 0.2, "num_gpus": 0})
to deploy it to the Ray cluster we have just defined. The min_workers and max_workers options, and the hardware requirements of your inference code will determine how your cluster autoscales; you don’t need to define complex pod or cluster autoscaling strategies.
Another key aspect of scaling a face recognition system is managing the storage, retrieval, and matching of face embeddings. For applications dealing with millions of individual identities, this becomes an important issue, since the trivial approach of storing every target embedding in memory, and trying to compute the distance metric across the whole database is too resource intensive. Luckily, we can use search engines like Elasticsearch to efficiently store and compute distance metrics at scale. Following this approach, we have two main options: 1) Computing the similarity metric for all entries by taking advantage of Elasticsearch script queries. 2) Using the KNN search option to run an approximate nearest neighbor search. When our database of individual identities is large enough, running approximate nearest neighbor searches ensures that our queries run efficiently. However, this ANN search may not always return the true K nearest neighbors, which makes scalability a trade off between matching speed, and accuracy.
Conclusion
Face recognition is a complex technology that encapsulates detection, alignment, representation, and matching algorithms. In this blog post we have described these typical steps of a face recognition pipeline, and we have explained popular algorithms that cover the most relevant stages. As we conclude our discussion on face recognition technology, it's clear that it has the potential to become an instrumental technology in many aspects of our daily lives. On one hand, recent advances in machine learning algorithms have made it possible to detect and match faces with human-like performance. On the other hand, scaling technologies have democratized the deployment of face recognition systems at a massive scale.
Ultimately, the future of face recognition technology will depend on how it's developed and implemented. By not only pushing the performance and scalability of face recognition systems, but also keeping ethical considerations at the forefront, we can harness the potential of this technology to create a better world for everyone.
