
10 ejemplos reales de uso de IA en diferentes industrias

La inteligencia artificial es mucho más que una moda pasajera, es una fuerza poderosa que está moldeando el futuro. Desde la industria manufacturera hasta el sector sanitario, la IA se ha convertido rápidamente en una parte integral de nuestra vida diaria, redefiniendo cómo interactuamos, trabajamos, y vivimos. Cada día que pasa, los algoritmos de IA continúan evolucionando y madurando, abriendo nuevas posibilidades, optimizando procesos, y mejorando nuestra experiencia en maneras que nunca habíamos creído posibles.
En este artículo, mostraremos 10 ejemplos específicos de cómo la IA está transformando diferentes industrias. Cada sección de este artículo cubrirá un caso concreto, señalando tanto las dificultades que la industria correspondiente sufría, y como la IA ha ayudado a superarlas. Además, también describiremos algunos de los algoritmos más populares en cada caso, y también mostraremos qué benchmarks se utilizan para evaluar su rendimiento.
Sin más preámbulos, aquí están nuestros 10 ejemplos de uso de la IA en diferentes industrias.
IA en la industria manufacturera: Uso de redes de segmentación para agilizar la inspección
El mundo de la ingeniería siempre ha perseguido maximizar la automatización, tratando de optimizar las tareas manuales para mejorar la productividad y maximizar los beneficios. Esta búsqueda incansable ha llevado a muchos early adopters a tratar de incorporar algoritmos de machine learning en sus procesos.
Uno de los principales consumidores de tecnología de procesamiento automatizado siempre han sido las fábricas de alta tecnología. Tradicionalmente, las líneas de producción en estas plantas incorporaban algoritmos de visión artificial rudimentarios que realizaban mediciones simples. Hoy en día, con la popularización de las redes neuronales profundas, las fábricas de alta tecnología han comenzado a incorporar soluciones de deep learning que agilizan aún más sus procesos de inspección.
Un ejemplo específico de cómo las fábricas están utilizando algoritmos inteligentes de inspección es el control de calidad. Los algoritmos de inspección para control de calidad se entrenan con miles de imágenes con tanto productos de buena calidad como defectuosos, y utilizando esta información, aprenden a identificar las características visuales que distinguen un producto defectuoso de uno bueno. Una vez entrenados, estos algoritmos pueden ser desplegados para analizar nuevas imágenes con un alto nivel de precisión y rapidez. Además, estos sistemas pueden funcionar las 24 horas del día sin descanso y mantener el mismo nivel de precisión.
Por lo general, el análisis automatizado de control de calidad se puede abordar utilizando tanto modelos de clasificación, como modelos de segmentación. Uno de los modelos de segmentación más populares de la última década ha sido U-Net, una red convolucional codificador-decodificador que primero comprime la información espacial en mapas de características de alta dimensión y luego los expande de nuevo al dominio espacial para generar el mapa de segmentación.
Además, los investigadores han recurrido a benchmarks como KollertorSSD para evaluar el rendimiento de los modelos de segmentación para la inspección de calidad. En estos bencharks, las redes de segmentación como U-Net han logrado un rendimiento casi humano, alcanzando un average precision de más del 96%. Este resultado indica que el modelo etiquetó correctamente más del 96% de los píxeles, etiquetándolos correctamente como superficies defectuosas o no defectuosas.
IA en medicina: Screening eficiente de retinopatía utilizando procesamiento de imágenes
La atención médica es otro campo en el que la innovación prospera constantemente. Avances tecnológicos clásicos como la transformada de Fourier abrieron el camino para crear sistemas complejos de imágenes en 3D, como las resonancias magnéticas. Hoy en día, el campo de la atención médica continúa adoptando innovaciones tecnológicas y ha comenzado a incorporar modelos de IA para revolucionar aún más sus servicios y mejorar la vida de los pacientes.
Las pruebas de diagnóstico suelen generar datos complejos, a menudo en forma de imágenes que requieren interpretación por expertos. Los especialistas estudian durante años para interpretar estas imágenes, pero las limitaciones de tiempo a menudo restringen su capacidad para analizar cada caso en detalle. Esto es especialmente evidente en enfermedades como la retinopatía diabética.
La retinopatía diabética, un tipo específico de retinopatía causada por daño a los vasos sanguíneos en la retina, es una complicación común de la diabetes y una de las principales causas de ceguera en adultos en edad laboral. Con la proyección de que el número de personas diagnosticadas con diabetes alcance los 600 millones en 2040, un tercio de los cuales se espera que desarrollen retinopatía diabética, la necesidad de un diagnóstico eficiente y preciso se vuelve cada vez más crítica.
Para prevenir la retinopatía diabética, se fomenta el screening de retina, y aquí es donde la IA puede ayudar. En lugar de depender de especialistas altamente cualificados, que podrían tener demasiada carga de trabajo, las imágenes de fondo de ojo adquiridas en las sesiones de cribado pueden analizarse utilizando modelos de machine learning. Algunos ejemplos de estas imágenes de fondo de ojo se pueden ver en la Figura 1.
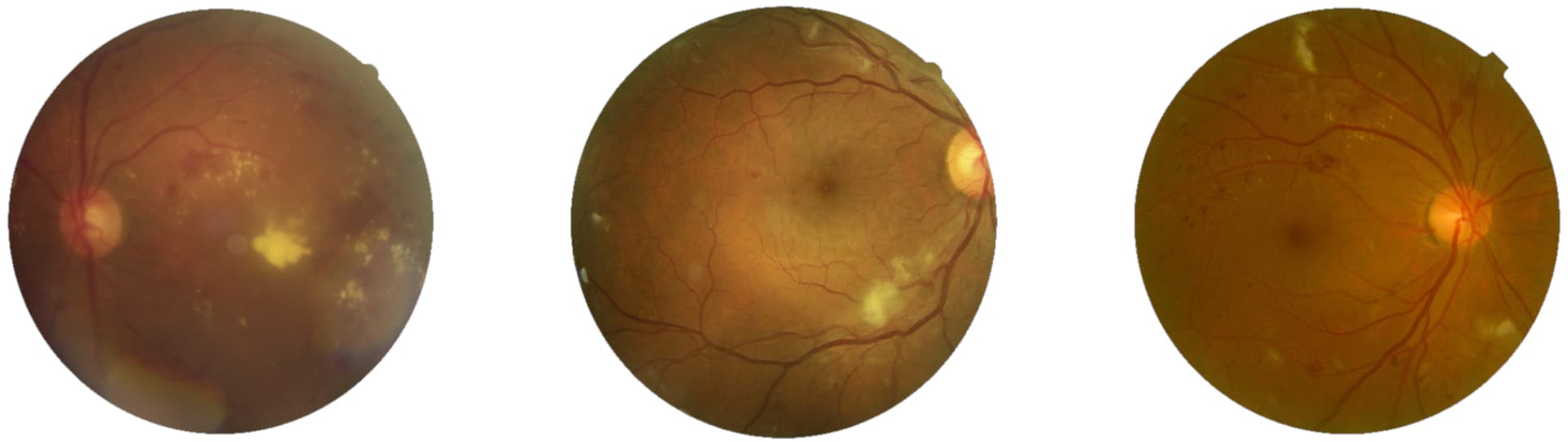
Los modelos de machine learning pueden ayudar a analizar imágenes de fondo de ojo principalmente de tres maneras. En primer lugar, está la detección automática, en la que un clasificador binario de aprendizaje automático intenta identificar la presencia de cualquier lesión de retinopatía sin cuantificarlas específicamente. En segundo lugar, los modelos de aprendizaje automático también se pueden utilizar para categorizar las diferentes etapas de la enfermedad, clasificando la gravedad de la retinopatía de acuerdo con la escala ICDR. Por último, un enfoque aún más elaborado para utilizar la IA en el cribado es generar mapas a nivel de píxel para marcar con precisión las lesiones típicas de la retinopatía, como microaneurismas, exudados blandos, exudados duros y hemorragias.
Al utilizar clasificadores de IA binarios para detectar retinopatía, los modelos más avanzados alcanzan una precisión de más del 92% en grandes conjuntos de datos como DDR, que cuenta con un total de 13671 imágenes de fondo de ojo.
IA en educación: Diseñando trayectorias de aprendizaje personalizadas para mejorar el éxito académico
A pesar de haber revolucionado muchos aspectos de nuestra sociedad, la aplicación de la IA en el campo de la educación todavía se encuentra en una etapa temprana. Históricamente, el sector educativo ha quedado rezagado en términos de adopción tecnológica al compararlo con el sector financiero, la atención médica, o la ingeniería. Estos sectores han integrado rápidamente tecnología de vanguardia en su núcleo operativo, aprovechando la IA para realizar análisis predictivo, brindar experiencias personalizadas de los clientes, o mejorar la atención a los pacientes. Mientras tanto, el sector educativo, que es igualmente vital, ha sido un poco más lento en la adopción de este tipo de avances.
Sin embargo, esto está cambiando. Aprovechando la potencia de los algoritmos de IA, podemos brindar una experiencia de aprendizaje hiper-personalizada para cada estudiante. No se trata tan sólo de presentar información ya existente en un formato adaptado, sino de también de transformar el aprendizaje en un proceso activo y práctico. Esto garantiza que el conocimiento adquirido no es solamente teórico, sino que se puede aplicar en escenarios realistas.
Un buen ejemplo de cómo se puede integrar la IA en la educación es la plataforma de aprendizaje Korbit. Esta innovadora plataforma de e-learning utiliza algoritmos de aprendizaje automático, procesamiento del lenguaje natural, y aprendizaje por refuerzo para brindar una experiencia de aprendizaje personalizada y atractiva. Cuando un estudiante se inscribe por primera vez en la plataforma, se realiza una evaluación inicial. Después, basándose en esta evaluación, los objetivos de aprendizaje y la disponibilidad del estudiante, la plataforma elabora una trayectoria de aprendizaje adaptada.
En esta trayectoria de aprendizaje, proponen ejercicios basados en la resolución de problemas. Se les presentan preguntas y pueden intentar resolverlas, pedir ayuda o saltarlas. Después de cada intento, un algoritmo de procesamiento del lenguaje natural verifica la respuesta del estudiante usando una solución como referencia. Si la respuesta de un estudiante es incorrecta, el sistema de IA proporciona guías personalizadas, como pistas y explicaciones, elegidas por modelos de aprendizaje por refuerzo en función del perfil y los intentos del estudiante.
Para evaluar la eficacia de su método, los investigadores de Korbit diseñaron un estudio comparativo en el que midieron los avances en el aprendizaje de estudiantes que utilizaron una plataforma MOOC convencional y la trayectoria de aprendizaje personalizada de Korbit. Después de recopilar datos de un total de 199 estudiantes, su análisis reveló que aquellos que se inscribieron en la plataforma Korbit experimentaron avances en el aprendizaje entre 2 y 2.5 veces mayores que aquellos en la plataforma MOOC.
IA en ciberseguridad: Yendo más allá de las firmas y heurísticas para la detección de malware
La carrera entre los cibercriminales y los expertos en ciberseguridad ha sido un constante tira y afloja durante décadas. A medida que las técnicas utilizadas por los cibercriminales evolucionaron, resultando en malware más avanzado que puede cambiar astutamente su apariencia mientras mantiene su potencial dañino, los expertos en ciberseguridad tuvieron que adaptarse y encontrar nuevas formas de contrarrestar estas amenazas.
Tradicionalmente, la detección de malware se realizaba mediante "firmas", cadenas de código especiales que eran únicas para cada pieza de malware. Sin embargo, a medida que el malware evolucionó, se volvió más difícil encontrar firmas que lo identificaran de manera eficaz. Un primer paso para superar este problema fue crear motores heurísticos que busquen comportamientos específicos que indiquen intenciones maliciosas. Sin embargo, este enfoque generalmente se basaba en reglas en las que los expertos tenían que definir e ingresar manualmente condiciones basadas en su conocimiento y experiencia. Cada regla era una especie de declaración "if-else" que señalaba ciertos comportamientos como potencialmente dañinos. No obstante, la principal desventaja de este enfoque es que su efectividad dependía en gran medida de la calidad y exhaustividad de las reglas definidas por los expertos.
Para superar las limitaciones de los motores de firmas y heurísticos, los expertos comenzaron a explorar cómo el machine learning podría ayudar a identificar patrones maliciosos mediante el aprendizaje automático de una base de datos de malware conocido. Bases de datos populares como EMBER incluyen información útil, como la distribución de diferentes bytes en un archivo, la información sobre cadenas de texto encontradas en el ejecutable y las ubicaciones de archivos importantes para ejecutar el software.
Con esta información, diferentes algoritmos de aprendizaje automático, como por ejemplo SVMs, random forests o redes neuronales profundas, han sido utilizados para realizar la identificación automática de malware, logrando una precisión de hasta el 95% en el conjunto de datos mencionado.
IA en agricultura: Monitorizando plagas de manera autónoma con modelos de detección
La agricultura es la base de nuestro sustento alimenticio, pero se enfrenta un gran adversario: las plagas de insectos. Estas plagas son responsables de alrededor del 30% de las pérdidas de producción agrícola en el mundo cada año, por lo que su control se ha convertido en un aspecto crucial de la agricultura intensiva. A lo largo de los años, el uso de pesticidas químicos ha demostrado ser la solución más rentable para la protección de cultivos contra estos pequeños invasores; sin embargo, su uso continuo ha llevado a la intoxicación de diferentes organismos y ha puesto el foco en diferentes problemas de salud.
Para tratar de evitar el uso excesivo de pesticidas, los agricultores han comenzado a monitorear las plagas. Este enfoque permite a los agricultores aplicar medidas de control de plagas solo cuando sea necesario, reduciendo así el volumen total de pesticidas utilizados. El enfoque más básico para llevar a cabo este monitoreo es colocar trampas adhesivas en lugares estratégicos dentro de los campos e invernaderos. Una vez colocadas, un experto puede revisarlas cada pocos días e identificar manualmente los insectos que han quedado atrapados. La Figura 2 muestra diferentes insectos capturados.

Las trampas adhesivas han demostrado ser un método eficiente para monitorear las poblaciones de plagas, pero la identificación y conteo manual de los insectos capturados puede ser excesivamente laboriosa. Para abordar estos problemas, los investigadores han desarrollado estaciones de monitoreo autónomas que incorporan cámaras colocadas frente a las trampas adhesivas. Estas cámaras están programadas para capturar imágenes de las trampas adhesivas a intervalos regulares y subirlas a la nube para su posterior análisis. Una vez subidas, se pueden utilizar algoritmos de aprendizaje automático, como YOLO, para identificar y contar los insectos capturados.
Como siempre, optimizar el rendimiento de los modelos de aprendizaje automático es crítico, y los investigadores han recurrido a conjuntos de datos a gran escala, como Pest24, para ello. Pest24 es un conjunto de datos que contiene más de 25000 imágenes anotadas obtenidas de trampas autónomas. A pesar de todos los esfuerzos que se han dedicado a refinar los modelos de aprendizaje automático, la detección de plagas ha demostrado ser un problema desafiante donde los resultados del análisis automatizado aún están lejos de ser ideales. Específicamente, el modelo YOLOv3 alcanzó un average precision del 59%, un logro útil, aunque todavía hay un margen sustancial de mejora.
IA en banca: Luchando contra el fraude de tarjetas utilizando árboles de decisión
El fraude con tarjetas de crédito es un problema que afecta continuamente al mundo de las finanzas. Tan solo en 2016, las transacciones fraudulentas con tarjetas de crédito ascendieron a la asombrosa cifra de 1.8 mil millones de euros. Existen varios tipos de fraude con tarjetas de crédito, como por ejemplo el fraude con tarjetas robadas, el fraude por insolvencia, o el fraude por solicitudes de tarjetas falsas. Sin embargo, el tipo más común probablemente sea el uso no autorizado de la información de la tarjeta de crédito para realizar compras.
Utilizando información de la tarjeta robada, como el número, el CVV, o la fecha de vencimiento, los estafadores pueden realizar rápidamente compras en línea antes de que el titular de la tarjeta se dé cuenta de que los datos de su tarjeta han sido robados. Debido al gran volumen de transacciones diarias con tarjeta, y la rapidez con la que se utiliza la información de la tarjeta una vez robada, las transacciones deben ser verificadas automáticamente utilizando sistemas en tiempo real capaces de identificar comportamientos sospechosos. Por esta razón, las compañías han comenzado a investigar cómo el aprendizaje automático puede reconocer qué transacciones son fraudulentas y cuáles no.
En el campo de la detección de fraude con tarjetas de crédito, los algoritmos de aprendizaje automático basados en árboles, como los árboles de decisión, los random forest o los gradient boosted trees, son bastante populares. Estos algoritmos descomponen el proceso de decisión en una serie de preguntas sobre características, al igual que un diagrama de flujo basado en árboles. Específicamente, en problemas de detección de fraude estas características suelen ser datos como el monto de la transacción, la ubicación, o la categoría del comerciante.
Uno de los datasets de detección de fraude con tarjetas de crédito más populares es el ULB. Este conjunto de datos contiene un total de 284807 transacciones, de las cuales solo 492 se identificaron como fraudulentas. Esto crea un escenario muy desequilibrado donde sólo el 0.17% de los datos pertenecen a la clase objetivo. Debido a esto, los investigadores a menudo utilizan métricas como el precision y recall, que son más adecuadas para estos escenarios.
Según las últimas investigaciones sobre la detección de fraude con tarjetas de crédito utilizando IA, modelos basados en árboles como los random forest son capaces de alcanzar una tasa de recall de alrededor del 81% en el dataset ULB. Esto significa que el modelo identificó correctamente el 81% de las transacciones fraudulentas.
IA en comercio: Utilizando sistemas de recomendación para impulsar las ventas en comercio electrónico
El comercio electrónico se ha convertido en una de las principales formas en que los consumidores adquieren bienes y servicios. Entre sus muchos beneficios, tres factores cruciales han impulsado su crecimiento exponencial. En primer lugar, la comodidad de navegar por tiendas digitalizadas ha permitido explorar amplios catálogos de productos desde cualquier dispositivo conectado a internet. En segundo lugar, la integración de pasarelas de pago digitales robustas ha garantizado la seguridad de las transacciones, aumentando la confianza del consumidor. En tercer lugar, el alcance global de las plataformas de comercio electrónico, sin restricciones geográficas, ha ampliado significativamente la base de consumidores.
Con el fin de maximizar el potencial de los negocios en línea, sitios de comercio electrónico tanto grandes como pequeños han tratado de incorporar motores de recomendación para impulsar aún más las ventas. Tal es la importancia de los motores de recomendación que, en el caso del gigante comercio electrónico Amazon, su motor de recomendación propietario es responsable de generar alrededor del 35% de sus ingresos totales.
Una manera típica en que estos motores de recomendación funcionan es mediante el uso de algoritmos de filtrado colaborativo. Estos algoritmos están diseñados para anticipar las preferencias del usuario en base a las preferencias de un colectivo de usuarios. En esencia, estos algoritmos se basan en los comportamientos y preferencias comunes de usuarios similares para sugerir productos relevantes. Para entenderlo más claramente, consideremos un escenario cotidiano en el que queremos elegir un producto para comprar. En la mayoría de los casos, recurrimos a nuestros amigos para obtener sugerencias, especialmente de aquellos amigos que comparten nuestros gustos, y confiamos inherentemente en sus recomendaciones porque entienden nuestras preferencias. Esto es precisamente cómo los algoritmos de filtrado colaborativo seleccionan los productos para anunciárselos a los usuarios.
Un benchmark popular en el campo de los sistemas de recomendación es el Amazon-book. Este conjunto de datos está compuesto por miles de reseñas de libros aportadas por usuarios, y el objetivo final es sugerir nuevos libros que se alineen con los intereses de un usuario, en base a sus reseñas existentes. En términos de rendimiento, el estado del arte actual muestra un top-20 recall de aproximadamente el 7%. Esto implica que, de los 20 libros sugeridos por el sistema de recomendación, el 7% son realmente relevantes según las preferencias del usuario atendiendo a su historial de reseñas.
IA en reclutamiento: Usando transformers para generar comunicaciones personalizadas
El panorama del reclutamiento también ha sufrido una fuerte revolución con los últimos avances tecnológicos. Los métodos de reclutamiento tradicionales, como escribir un mensaje genérico y enviarlo a cientos de candidatos, están quedando obsoletos con modelos de IA para generación de texto como los transformers.
Estos transformers se entrenan con grandes cantidades de secuencias de texto, y aprenden un modelo de lenguaje que puede tanto entender como generar texto. Dado que gran parte de la información utilizada para entrenarlos ha sido extraída de internet, las redes transformers son particularmente buenas analizando la información de sitios web como LinkedIn. Esta capacidad de procesar texto crudo es particularmente beneficiosa en el panorama del reclutamiento, donde los posibles candidatos presentan sus habilidades, experiencias y aspiraciones de formas muy poco estandarizadas.
Una vez analizado el perfil de un posible candidato, los transformers pueden generar mensajes personalizados para interactuar con ellos. Puedes pedirle a modelos como ChatGPT “Genera un mensaje personalizado para reclutar a este candidato. Aquí está la información pública de LinkedIn: [Pega la información aquí]”. ChatGPT generará un mensaje personalizado basado en los antecedentes, intereses, y el rol específico para el cual el candidato podría ser adecuado. Por ejemplo, un mensaje para un candidato con experiencia en ciencia de datos podría destacar los proyectos innovadores que tu organización está llevando a cabo, o cómo su experiencia se alinea con las necesidades de tu empresa. Estos mensajes personalizados pueden mejorar significativamente las tasas de respuesta, ya que los candidatos se sienten reconocidos y valorados cuando reciben un mensaje hecho específicamente para ellos.
Cuando los reclutadores desean automatizar aún más el proceso de reclutamiento, pueden volver a recurrir a los transformers, esta vez afinados para generar automáticamente mensajes de diálogo. En este caso, transformers como BERT son capaces de formular respuestas que están influenciadas por los mensajes del candidato. Un benchmark popular para evaluar estos transformadores de diálogo es el conjunto de datos Persona-Chat, que incluye más de 10000 diálogos. En este benchmark, los modelos del estado del arte alcanzan un F1 de más del 21%, lo que significa que hay más de un 20% de coincidencia entre los mensajes de referencia y los mensajes generados.
IA en moda: Revolucionando las compras en línea con probadores virtuales
En una década marcada por la rápida expansión de la IA, la industria de la moda no está al margen de esta tecnología disruptiva. Hoy en día, las compras en línea están lejos de ser una novedad, la popularización de internet ha abierto un amplio abanico de posibilidades, y las tiendas minoristas han adoptado esta tecnología para llegar a una audiencia global. Sin embargo, cuando navegas por una tienda en línea, puede que no estés seguro de si una prenda te quedará bien. Ahora imagina que puedes encender tu cámara, subir una foto y ver cómo te quedaría sin salir de la comodidad de tu hogar. Este probador virtual podría ser el aliado perfecto en un mercado de moda en línea altamente competitivo.
Los probadores virtuales utilizan inteligencia artificial para crear una imagen de un cliente vistiendo un artículo específico, usando solo una foto del cliente y una foto del producto. El modelo de IA intentará generar una nueva imagen en la que se conserve la pose del cliente, pero ahora vistiendo el producto seleccionado. Además, estos sistemas intentarán conservar aspectos como las condiciones de iluminación, el fondo, las auto-oclusiones u otros detalles presentes en la foto original.
Uno de los benchmarks más populares para este tipo de modelos es el conjunto de datos VITON. Este conjunto de datos tiene más de 10000 ejemplos, donde cada muestra tiene una imagen frontal de una persona, una prenda objetivo y la misma persona vistiendo esta prenda. Este tipo de modelos puede ser complicado de evaluar y, además de un benchmark, los investigadores tienen que diseñar cuidadosamente una métrica para medir su rendimiento. En este caso, una métrica popular es la puntuación FID, que utiliza las activaciones internas de una red Inception preentrenada para comparar cuán similares son dos imágenes: cuanto más cercanas estén las activaciones, más similares serán las imágenes. Aquí, el modelo con la puntuación más alta logra un FID inferior a 10 y, dado que esta métrica puede ser difícil de comprender, la Figura 3 muestra imágenes generadas utilizando uno de los modelos de mejor rendimiento.

IA en marketing: Optimización de campañas mediante la predicción de la tasa de clics
Se espera que el gasto total en publicidad digital alcance los $455.3 mil millones en 2023. De esa cantidad, el 55.2% se destinará a publicidad display y el 40.2% a búsqueda. Con los formatos digitales acaparando la mayor parte del presupuesto publicitario, los especialistas en marketing necesitan optimizar continuamente la efectividad de sus campañas.
Para medir la efectividad de sus campañas, los especialistas en marketing suelen recurrir a métricas como la tasa de clics. Esta métrica se calcula dividiendo el número de clics entre el número de impresiones y expresando el resultado como un porcentaje y, según estudios recientes, la tasa de clics promedio en Google AdWords en todas las industrias es del 3.17%.
Para optimizar el retorno de la inversión, los especialistas a menudo diseñan cuidadosamente sus campañas para maximizar la tasa de clics, y aquí es donde entra en juego la IA. En lugar de depender únicamente de su experiencia, que a veces puede ser limitada, pueden recurrir a modelos de aprendizaje automático para predecir cómo de bien funcionará una campaña de marketing.
Los modelos de IA para predecir la tasa de clics a menudo se entrenan y evalúan en benchmarks como Criteo, un conjunto de datos que incluye más de 45 millones de muestras. Cada muestra en este conjunto de datos contiene 13 características numéricas y 23 categóricas, junto con la tasa de clics para el anuncio correspondiente.
Uno de los modelos de aprendizaje automático con mejor rendimiento para el benchmark Criteo es un modelo basado en perceptrón multicapa de dos flujos llamado FinalMLP. Cuando se evalúa utilizando el área bajo la curva ROC, este modelo alcanza una puntuación del 81%. Esto muestra cómo de bien bien se correlacionan las predicciones y las anotaciones del conjunto de datos utilizando una secuencia de umbrales de tasa de clics para diferenciar entre anuncios “positivos”, aquellos por encima del umbral de tasa de clics, y anuncios “negativos”, aquellos por debajo del umbral.
Conclusión
La integración de la Inteligencia Artificial en la industria representa un gran avance en la optimización de la eficiencia, precisión y comodidad. Desde la automatización de procesos tediosos en ingeniería hasta la mejora en el diagnóstico en el ámbito sanitario, la IA está remodelando nuestro mundo y redefiniendo nuestro futuro.
