
¿Qué es la IA generativa y cómo funciona la IA que escribe y genera imágenes?

La IA generativa es un campo de la inteligencia artificial que está creciendo rápidamente y que tiene como objetivo crear nuevo contenido, como por ejemplo imágenes, texto o música. Esta tecnología tiene el potencial de revolucionar la forma en que creamos y consumimos contenido, y ya se está utilizando en diferentes sectores, como el arte, el entretenimiento y el marketing.
En este post exploraremos las diferentes formas en que la IA generativa se utiliza para crear nuevo contenido en diferentes dominios. Pondremos especial atención a las dos modalidades más populares de IA generativa: IA para escribir texto, e IA para generar imágenes. También explicaremos, de manera breve pero técnica, los principales sistemas de IA generativa en estas modalidades, como son ChatGPT y Stable Diffusion.
Muchos usuarios han empezado a interactuar con modelos de IA generativa a través de aplicaciones web, pero es posible que no entiendan completamente qué son estos modelos y cómo funcionan. Este post pretende abordar esta brecha y ayudarle a aprender más sobre el campo de la IA generativa y las principales técnicas que se utilizan.
¿Qué es la IA generativa?
Antes de empezar a hablar de IA generativa, deberíamos intentar comprender el concepto de IA primero. A muchos investigadores no les suele gustar el término IA, ya que a menudo se utiliza para exagerar las capacidades del machine learning. De hecho, la mayoría de la IA que vemos hoy en día es en realidad machine learning. Entonces, ¿qué es el machine learning? El machine learning es simplemente una forma de enseñar a los PCs a generar salidas utilizando muestras de datos. Estas muestras suelen ser texto, imágenes o audio, y las salidas suelen ser una etiqueta, un valor numérico, u otra imagen, texto o audio. Una vez entrenados, estos algoritmos pueden analizar nuevas muestras, nunca antes vistas, con una precisión impresionante.
La IA generativa es un subconjunto del machine learning que tiene como objetivo generar nuevo contenido, como audio, imágenes o texto. Los modelos de IA generativa utilizan arquitecturas especializadas, por ejemplo transformers, redes generativas adversarias o redes encoder-decoder, que pueden aprender con datos de entrenamiento y producir creaciones realistas y novedosas que reflejan las características de los datos sin replicarlos por completo.
La IA generativa trae consigo un gran potencial para la creación de contenido, ya que puede agilizar el proceso creativo, especialmente en las etapas de ideación de borradores. Ya sea una publicación para redes sociales, una imagen para un blog, o música de fondo, la IA generativa puede ayudarte a crear borradores rápidos y de alta calidad que te facilitarán el trabajo.
IA generativa que escribe texto
Las aplicaciones con IA para escribir texto como GhatGPT han ganado gran popularidad recientemente. Sin embargo, antes de ellas, los clasificadores de texto habían sido la familia dominante de IA para procesamiento de texto. Los clasificadores de texto asignan una categoría a un texto, por ejemplo "reseña positiva" o "reseña negativa". Estos modelos son realmente útiles, ya que pueden agilizar tareas como el servicio de atención al cliente, donde el modelo puede categorizar automáticamente las quejas en función del equipo que debe abordarlas.
Sin embargo, en los últimos años ha aparecido una nueva tendencia, mientras que los modelos anteriores sólo podían clasificar el texto, la IA generativa que escribe y es capaz capaz de seguir instrucciones simples se ha vuelto más popular. Estos modelos capaces de seguir instrucciones son fundamentalmente autosupervisados, lo que significa que no dependen de datos etiquetados por humanos, sino que crean sus propias etiquetas a partir de los datos. Esto reduce la necesidad de etiquetar manualmente los datos de entrenamiento, lo que facilita el uso de conjuntos de datos cada vez más grandes. De esta forma, pueden aprender con grandes cantidades de datos de texto no etiquetados, como páginas web, libros, noticias y más.
Al procesar grandes cantidades de datos, los métodos autosupervisados pueden acumular conocimiento y ayudarnos a completar tareas cotidianas como responder preguntas. Sin embargo, aunque los algoritmos autosupervisados son capaces de acumular una gran cantidad de conocimiento, se suele necesitar refinarlos para alcanzar el nivel de interactividad de aplicaciones como ChatGPT, Bing Chat o Bard.

ChatGPT
ChatGPT es un chatbot capaz interaccionar con una capacidad casi humana. OpenAI lo lanzó a finales de 2022 y se hizo increíblemente popular de la noche a la mañana. La principal razón del éxito de ChatGPT fue su capacidad para generar respuestas coherentes a peticiones escritas con lenguaje natural; tan solo solo escribes tu instrucción y ChatGPT te proporcionará una respuesta. Además, puedes usar ChatGPT de forma gratuita con Bing Chat.
ChatGPT funciona con un transformer, un tipo de modelo de aprendizaje automático que ha ido ganando popularidad desde 2017. Los transformers son muy buenos en tareas de procesamiento de lenguaje natural, como la elaboración de resúmenes, la traducción automática o la respuesta a preguntas. Estas redes utilizan un mecanismo llamado atención, que les permite aprender cómo están relacionadas las diferentes palabras de una secuencia. Esto los hace adecuados para tareas de NLP en las que el significado de una frase depende del contexto de las palabras que la rodean.
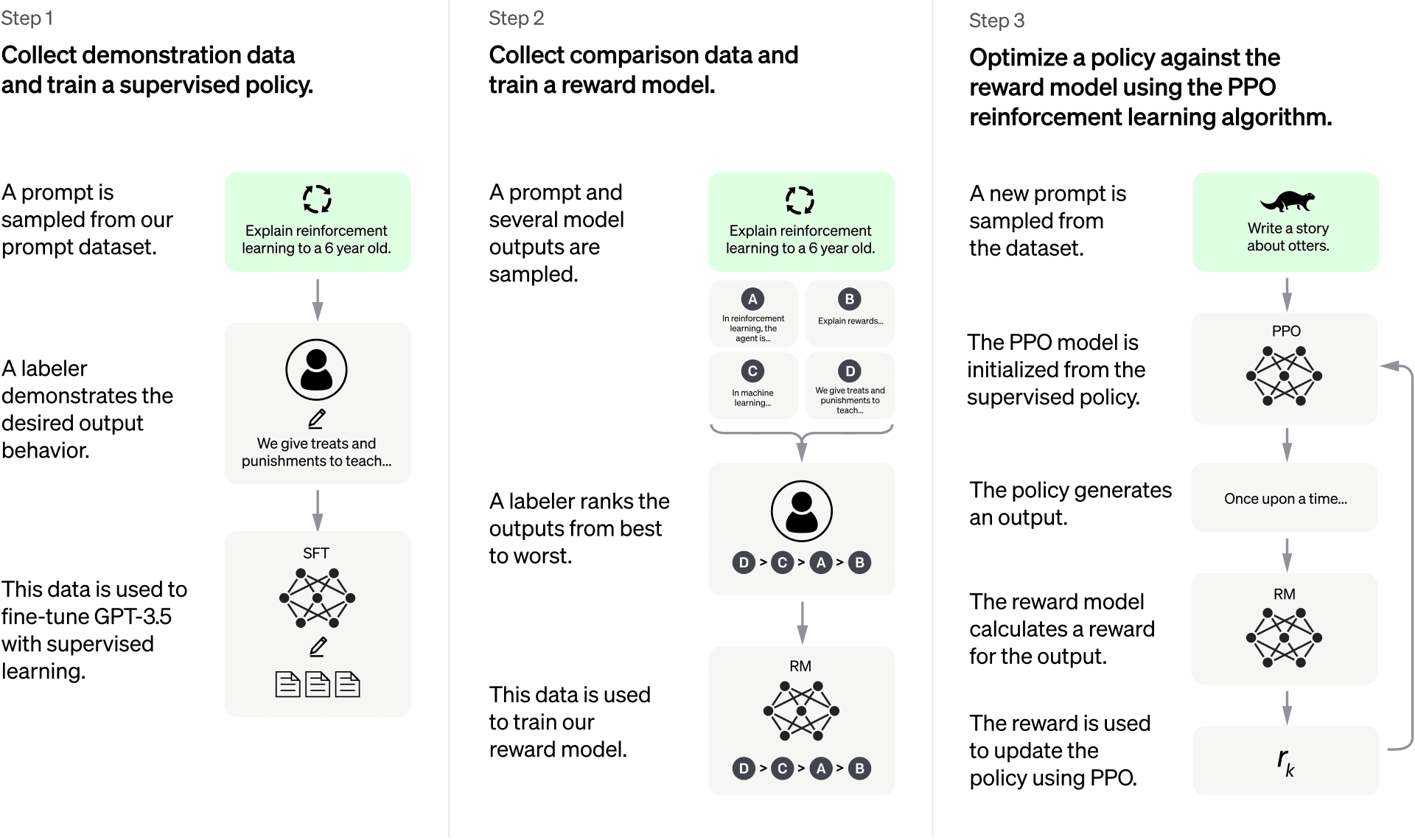
Sin embargo, la capacidad de modelado de lenguaje de los transformers no es suficiente por sí misma para entrenar un chatbot de uso general. Modelos como ChatGPT suelen entrenarse utilizando un enfoque con varios pasos. Específicamente, este chatbot primero se entrena con el objetivo de continuar frases de forma auto-supervisada, luego se entrena con pares de instrucciones-respuestas redactados de forma manual, y finalmente se refina utilizando aprendizaje por refuerzo.
Siguiendo este enfoque, el primer paso es construir un modelo de lenguaje capaz de completar frases. Esto se logra entrenando el transformer de forma semi-supervisada, alimentando al modelo con un corpus grande de libros, blogs y otra información que se encuentra en Internet. El resultado de la fase esta fase de preentrenamiento es un modelo de lenguaje grande (LLM), a menudo conocido como un modelo preentrenado.
Ahora mismo, este modelo preentrenado es muy bueno completando frases, pero no es tan bueno siguiendo instrucciones. Cuando se le pide "Escribe un poema", podría responder "dijo el poeta", esto se debe a que las narraciones son más frecuentes en Internet que las secuencias de instrucciones-respuestas. Para superar esta limitación, el LLM preentrenado se refina con un conjunto de pares de instrucciones-respuestas construidos de forma manual. En este paso, también conocido como “behavior cloning”, la representación interna de conocimiento del LLM se modifica ligeramente, consiguiendo así que sea más probable que responda a las instrucciones en lugar de simplemente completar frases.
Finalmente, una vez que el LLM ha sido refinado utilizando pares de instrucciones y respuestas creados manualmente, este se suele someter a un último paso de refinado. En este último paso, el modelo se mejora utilizando el aprendizaje por refuerzo, un tipo de entrenamiento que permite a los modelos aprender dejando que generen respuestas completas, y evaluándolas con un modelo de recompensa. Este modelo de recompensa es en sí mismo otro modelo de machine learning, entrenado para clasificar diferentes respuestas a un prompt y, al utilizar este modelo de recompensa, el generador de texto puede mejorar su rendimiento un poco más. Un prompt puede tener varias respuestas buenas, pero algunas de ellas pueden ser mejores que otras, y este paso prioriza precisamente eso: seleccionar la mejor respuesta entre las posibles. También es cierto que diferentes personas pueden tener diferentes opiniones sobre cómo clasificar las respuestas, esta puede ser la razón por la que ChatGPT, muestra un botón de me gusta/no me gusta junto a cada respuesta; de esta manera, la aplicación puede recopilar datos sobre las preferencias de sus usuarios.
IA generativa que crea imágenes
La IA generativa de texto a imagen es una clase especial de IA que puede producir imágenes a partir de descripciones escritas con lenguaje natural. Aunque estos modelos no han recibido tanta atención como ChatGPT, en los últimos años han aparecido numerosas aplicaciones online que permiten generar imágenes, y ahora existen numerosas opciones interesantes que pueden generar imágenes impresionantes.
En realidad, la IA que genera imágenes ha existido durante bastante tiempo. Sin embargo, como en el caso de los modelos de IA para el procesamiento de lenguaje, estos modelos más antiguos no eran tan poderosos como los que tenemos ahora. Dos buenos ejemplos de IA más antigua para la generación de imágenes son las GANs y el neural style transfer.
Las GAN, o redes generativas adversariales, que se presentaron en 2014 en el artículo "Generative Adversarial Networks", funcionan poniendo dos redes neuronales a competir entre sí. Una red, la generadora, intenta crear nuevas imágenes que no se distingan de las imágenes reales. La otra red, el discriminador, intenta distinguir entre imágenes reales e imágenes falsas creadas por el generador. Estas dos redes se entrenan juntas hasta que se alcanza un empate, es decir, que el generador puede engañar al discriminador la mitad de las veces. De este modo, podemos entrenar un generador de imágenes que, al menos, pueda engañar a los clasificadores de imágenes de la IA, aunque los resultados a veces disten mucho de ser perfectos.
Otro ejemplo de IA más antigua para generar imágenes es la técnica llamada neural style transfer. Introducida en 2016, esta técnica puede crear nuevas imágenes que imitan un estilo específico, preservando el contenido de las fotos que elijamos. Por ejemplo, si tenemos una foto de una ciudad y un cuadro de Van Gogh, podemos usar Neural Style Transfer para crear una nueva imagen que tenga los mismos edificios y calles que la foto, pero con las pinceladas y colores del estilo de Van Gogh. Esta técnica consiste en alimentar una red preentrenada con el estilo y la imagen de referencia, e ir modificando la imagen de referencia para que las activaciones neuronales del estilo se acerquen más a las de la imagen del estilo.
Sin embargo, ninguna de estas técnicas puede igualar la complejidad de los generadores de imágenes modernos como Midjnourney o, como alternativa gratuita, Stable Diffusion. Estos nuevos modelos se entrenan con conjuntos masivos de pares texto-imagen, lo que les permite crear imágenes mucho más realistas y detalladas.

Stable Diffusion
Una de las herramientas más populares de IA generativa para generar imágenes es Stable Diffusion. Stable Diffusion es un modelo que se puede usar fácilmente con aplicaciones como Web UI, y permite a los usuarios generar imágenes con instrucciones de texto. Por ejemplo, puedes escribir "Un gato sentado en una valla" y la interfaz web de Stable Diffusion mostrará una imagen de un gato sentado en una valla generada por el modelo de IA.
Stable Diffusion, al contrario que ChatGPT, es un modelo open source, lo que nos permite conocer a fondo sus funcionamiento. Este modelo de IA se basa en una técnica llamada latent diffusion, que consiste en añadir y eliminar ruido a imágenes de forma controlada. El modelo aprende a crear imágenes realistas invirtiendo el proceso de adición de ruido, partiendo de ruido aleatorio y eliminándolo gradualmente hasta llegar a la imagen deseada.
Este proceso de difusión inversa, que elimina iterativamente el ruido de una imagen aleatoria, se lleva a cabo utilizando una arquitectura U-Net. U-Net es un tipo de red convolucional que se diseñó originalmente para segmentar imágenes biomédicas, pero que también es capaz de generar imágenes RGB. Esta red suele entrenarse de forma supervisada, con pares imagen-imagen que, en este caso, serán la imagen ruidosa y el ruido que queremos eliminar en el paso actual de difusión inversa. Al entrenar el modelo, la U-Net aprende a predecir el ruido que estamos añadiendo en cada paso de difusión; luego, durante la inferencia, las predicciones de ruido generadas por la U-Net pueden utilizarse para invertir el proceso de difusión, sustrayendo el ruido de la imagen y recuperando así una imagen nítida a partir de ruido aleatorio.
Sin embargo, utilizar directamente la U-Net para procesar imágenes se volvería rápidamente prohibitivo para imágenes de tamaño moderado a grande. Si nos fijamos en el artículo original de U-Net, los autores utilizaron imágenes de 512x512 píxeles para los requisitos de memoria, pero ese tipo de imágenes ya sería prohibitivamente caro para Stable Diffusion, que tiene capas adicionales alrededor de U-Net. En lugar de trabajar directamente con los píxeles de la imagen, Stable Diffusion trabaja en un espacio latente, una representación comprimida que almacena la información de la imagen procesada en una menor cantidad de "píxeles". Para ello se utiliza un variational autoencoder, un tipo de red encoder-decoder que se entrena para producir la misma imagen con la que se alimenta. Una vez entrenada, podemos introducir una imagen al modelo y utilizar las activaciones internas de la red como representación comprimida de la imagen. Si nos limitamos a guardar el bloque de características que se encuentra entre el encoder y el decoder, podemos realizar la difusión inversa sobre él y ahorrar una enorme cantidad de recursos computacionales.
Incluso con todo este procesamiento, el modelo aún no es capaz de seguir indicaciones de texto, todavía tenemos que condicionar el proceso de difusión inversa. Para conseguirlo, se añaden capas de cross-attention a las secciones de codificación y decodificación de la U-Net. Estas capas de cross-attention funcionan de forma similar al mecanismo de self-attention utilizado por ChatGPT, pero tienen en cuenta tanto la información textual del prompt como la información visual del diffuser. De este modo, las activaciones de cada capa de la arquitectura U-Net original se proyectan utilizando el prompt textual.
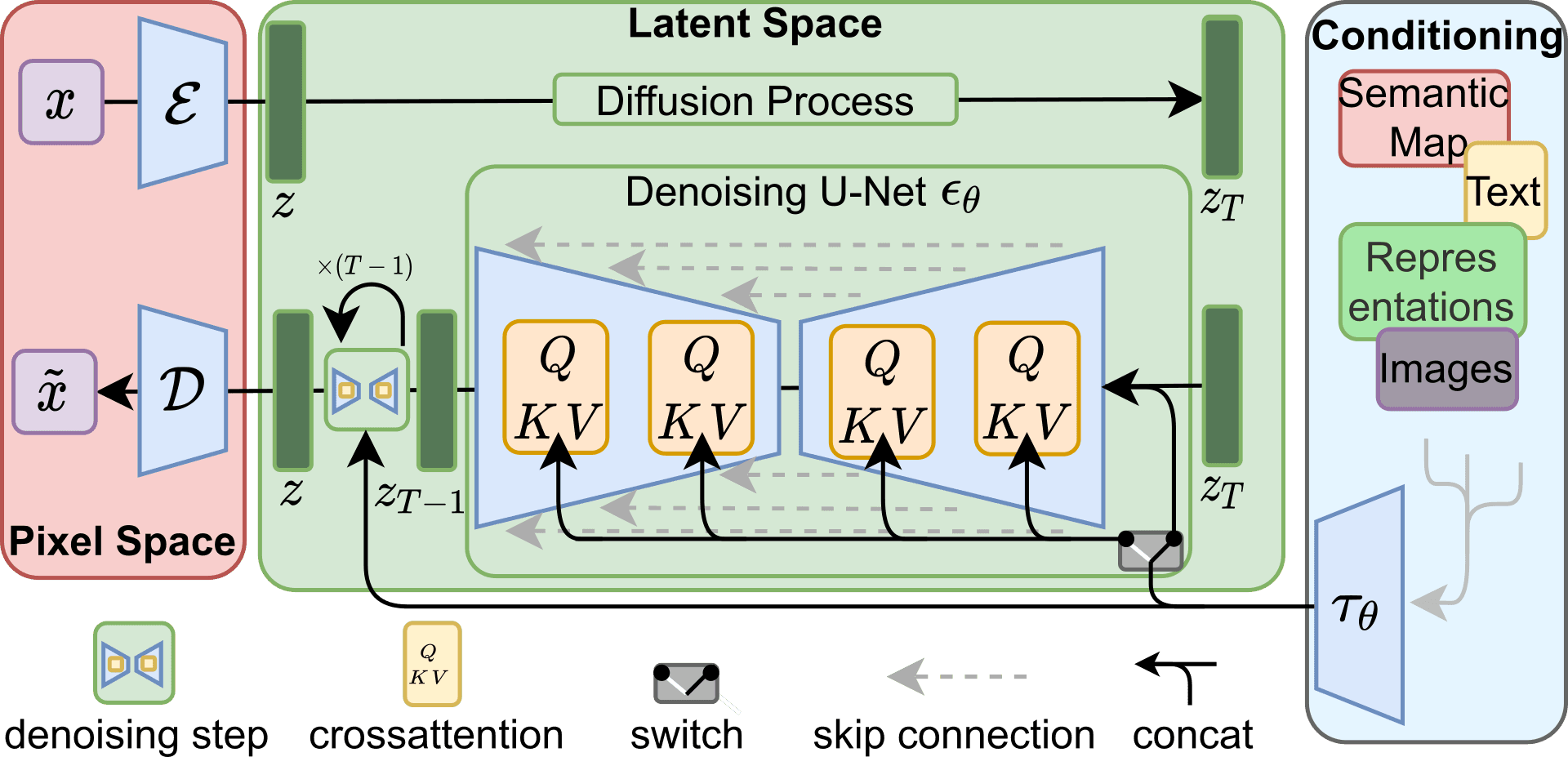
Si juntamos estos tres componentes: la U-Net, el variational autoencoder y las capas de cross-attention, obtenemos un modelo que puede generar imágenes de alta calidad siguiendo prompts.
Conclusión
La IA generativa es una tecnología disruptiva que promete revolucionar la creación de contenidos. Este tipo de IA puede producir contenidos sorprendentes y originales en diferentes ámbitos, como imágenes, texto o música, y la gente ya está aprovechando sus capacidades a través de aplicaciones como ChatGPT o Stable Diffusion Web UI. En este artículo hemos introducido el concepto de IA generativa y explorado las principales aplicaciones que la gente está utilizando para sacar partido de esta tecnología: Stable Diffusion, para generar imágenes, y ChatGPT, para escribir texto.
A medida que esta tecnología mejora, podemos esperar aplicaciones aún más sorprendentes y creativas en los próximos años. Por lo de ahora, la foto de portada de este post se creó con Stable Diffusion. Además, estos modelos están ayudando a trabajos creativos como los de marketing a escribir titulares, eslóganes o descripciones pegadizas.
Esperamos que esta entrada del blog te haya ofrecido una visión general de las diferentes formas en que se está utilizando la IA generativa, y cómo funcionan los modelos que permiten escribir texto y crear imágenes. Si estás interesado en saber más sobre los modelos de IA generativa y cómo pueden ayudarle en sus proyectos, no dudes en ponerte en contacto con nosotros a través de la página de contacto o el botón de chat.
