
Una breve introducción a la IA explicable

La inteligencia artificial es una tecnología revolucionaria que está transformando la forma en la que trabajamos, vivimos e interactuamos. Sin embargo, los sistemas de IA son cada vez más complejos, esto los vuelve más opacos y hace que sea difícil razonar sobre ellos. La manera típica de evaluar la fiabilidad de modelos de machine learning ha sido durante años construir conjuntos de datos de evaluación, definir alguna métrica, y calcular el valor de esa métrica para el conjunto de evaluación. Sin embargo, a muchos usuarios ya no les basta con estas métricas y necesitan un conocimiento más profundo de cómo los modelos llegan a los resultados. Así es como nació el campo de la inteligencia artificial explicable, o explainalbe AI (XAI) en inglés.
En este post introduciremos el concepto de IA explicable, mostrando diferentes tipos de IA explicable y describiendo algunos algoritmos populares como Grad-CAM, LIME, or SHAP.
¿Qué es la IA explicable?
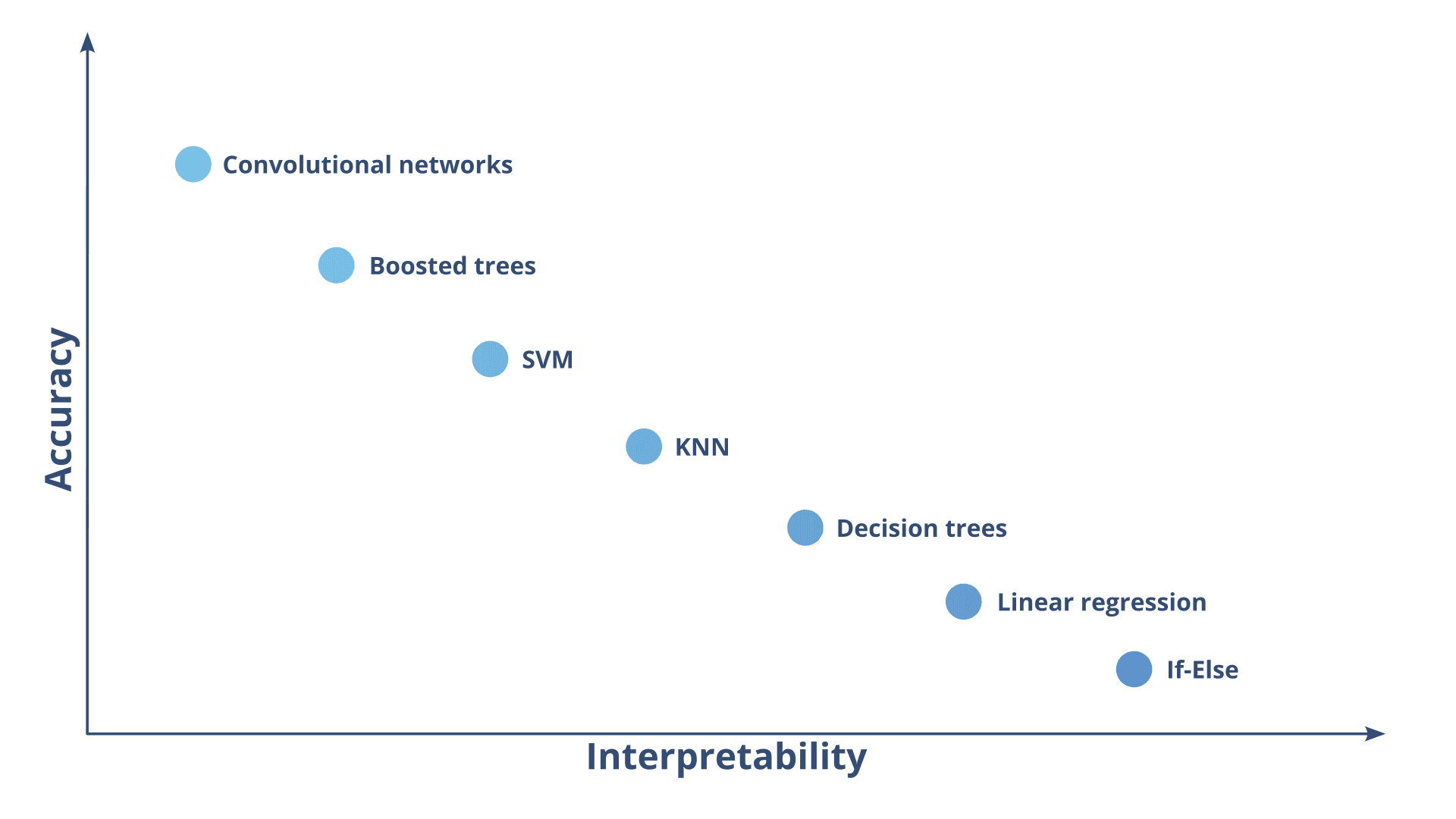
La IA explicable, o XAI, es un término algo genérico que engloba un conjunto de métodos que intentan mostrar por qué un algoritmo de IA está produciendo unos resultados concretos. A medida que los algoritmos de IA se vuelven más potentes, también tienden a volverse más opacos. Esta opacidad es la que llevó a los investigadores a acuñar el término “caja negra”, refiriéndose a modelos en los que es difícil entender por qué generan ciertos resultados. La Figura 1 muestra un gráfico que ilustra el típico equilibrio entre precisión e interpretabilidad.
Los modelos de caja negra son difíciles de aplicar en ciertos campos, como medicina o finanzas, en los que suele ser necesaria la supervisión humana. Sin embargo, para que esta supervisión sea eficaz, los usuarios deben de tener herramientas para verificar los resultados del modelo. Los usuarios deberían de ser capaces de saber por qué un préstamo se aprobó, o por qué un tratamiento se seleccionó. Estos son algunos ejemplos de por qué la IA explicable ha ganado tanta popularidad tras la aparición de modelos de caja negra de deep learning.
De todas formas, el término “IA explicable” no solo aplica a modelos de caja negra, ya que es un término bastante amplio sin un ámbito consolidado. Por ejemplo, el término “explicable” se suele asociar con algoritmos de postprocesado que analizan modelos de caja negra. Por otra parte, el término “interpretable” se suele utilizar para referirse a modelos que ellos mismos pueden dar algún tipo de explicación.
Gracias a los algoritmos de IA explicable, podemos encontrar sesgos en cómo operan los modelos, y caracterizar mejor sus resultados. Los algoritmos de IA explicable son una herramienta fundamental para aquellas organizaciones que sospechan que un modelo puede estar dando respuestas engañosas, y quieren ganar confianza antes de ponerlo en un entorno de producción.
¿Por qué importa la IA explicable?
La explicabilidad e interpretabilidad son cruciales en el campo de la IA porque permiten que los humanos entendamos y confiemos en las decisiones tomadas por los sistemas inteligentes. Sin un conocimiento profundo, los usuarios pueden desconfiar o incluso temer a la IA.
Cuando la IA se aplica en tareas críticas, como por ejemplo la puntuación de crédito en EEUU, la explicabilidad no es solo importante, sino que también es necesaria. Los prestamistas deben notificar a sus clientes sobre las razones concretas por las que se les denegó un crédito. Otro ejemplo es el uso de información personal para realizar inferencias automáticas en Europa; en este caso, los usuarios tienen el derecho de obtener una explicación de las decisiones tomadas usando sistemas automatizados que usan su información personal, y producen efectos que los afectan de manera significativa.
Las regulaciones pueden ser un buen motivo para intentar implementar algoritmos de IA explicable, pero no son el único buen motivo. Por ejemplo, un modelo podría recomendar un tratamiento para un paciente, y puede que el doctor no esté de acuerdo. A primera vista, podríamos decir que el modelo de IA se ha equivocado y ya está, sin embargo, si el modelo es capaz de explicar sus deducciones, el doctor podría acabar identificando alguna variable que descuidó, y finalmente darle la razón al modelo.
La explicabilidad también ayuda a identificar y atajar sesgos en sistemas inteligentes. Si un sistema con IA está tomando decisiones basado en datos o algoritmos sesgados, la explicabilidad puede ayudar a identificar de dónde vienen esos sesgos, y cómo atajarlos. Esto es fundamental, ya que un sistema inteligente sesgado puede ayudar a perpetuar, o incluso amplificar, ciertas desigualdades.
La taxonomía de la IA explicable
IA explicable es un término algo vago que se utiliza para englobar diferentes técnicas que tratan de aumentar la confianza que los usuarios tienen en los modelos de machine learning. Para tratar de entender mejor el amplio espectro que engloba el campo de la IA explicable, esta sección tratará de mostrar diferentes técnicas de IA explicable. Estas técnicas se han categorizado atendiendo a cuatro criterios: 1) Intrínseca o post hoc. 2) Específicas para un modelo o agnósticas. 3) Explicaciones locales o globales. 4) Resultados de la explicación.
Intrínseca o post hoc
Algunos modelos de machine learning tienen propiedades intrínsecas que los hacen interpretables. Dos ejemplos populares son los modelos lineales y los árboles de decisión. Cada uno de los pesos en un modelo lineal puede interpretarse como la importancia de la correspondiente característica. Por otro lado, la ganancia de información media de los nodos que usan una característica concreta en un árbol de decisión, puede usarse como un indicador de la importancia de dicha característica.
Sin embargo, lamentablemente la mayoría de los algoritmos de machine learning no tienen una manera explícita de reflejar la importancia de cada característica. Para interpretar estos modelos, debemos utilizar un algoritmo extra que genere explicaciones atendiendo a cómo se comporta el modelo.
Específica de un modelo o agnóstica
Algunas técnicas de explicabilidad se pueden aplicar a cualquier modelo de machine learning, mientras que otras solo se pueden aplicar a modelos específicos.
Un ejemplo común de técnica específica para un modelo es Grad-CAM, que usa los mapas de activación de capas convolucionales para generar explicaciones. Si un modelo no tiene capas convolucionales, o si las capas convolucionales no están dispuestas de cierta forma, Grad-CAM no se podrá aplicar.
Por otro lado, algoritmos como LIME o SHAP se pueden aplicar a cualquier modelo. Estos algoritmos inspeccionan el modelo de IA como una caja negra, y juegan con las entradas y salidas del modelo para generar explicaciones.
Centrado en una muestra o en todo el modelo
Algunas técnicas de explicabilidad se enfocan a explicar resultados concretos de un modelo para una muestra. Por ejemplo, Grad-CAM genera mapas de activación para una imagen concreta después de haberla procesado con la red convolucional.
Por otra parte, existen otras técnicas de explicabilidad que tratan de generar explicaciones a nivel de modelo. SHAP es un buen ejemplo de esto, ya que trata de determinar la importancia de cada característica de un dataset en conjunto a través de valores Shapley.
Explicación resultante
Diferentes técnicas de explicabilidad generan diferentes tipos de explicaciones. Algunas técnicas generan resúmenes de características como, por ejemplo, un número que indica la importancia de cada característica. Otras técnicas consisten en extraer la información interna de ciertos modelos como, por ejemplo, los pesos de cada característica en un modelo lineal. Por último, otro ejemplo es el uso de modelos simples, interpretables, que aproximan los resultados de otro modelo más complejo, de caja negra; este tipo de modelos simplificados se suelen denominar subrogados.
Ejemplos de IA explicable
Ya hemos visto la amplia variedad que hay en el campo de la IA explicable, sin embargo, a lo largo de los últimos años algunos algoritmos se han popularizado especialmente. Ciertos métodos como SHAP han ganado un montón de atención gracias a su amplia aplicabilidad, mientras que métodos tradicionales de interpretabilidad como inspeccionar internamente los árboles de decisión se han mantenido populares ya durante décadas. En esta sección daremos breve introducción a algunos algoritmos populares de IA explicable.
Árboles de decisión
Los árboles de decisión son una técnica popular de machine learning para trabajar con datos no lineales. Estos árboles dividen los datos iterativamente en forma de ramificaciones. Cada nodo del árbol representa una decisión, en la que un valor de corte para cierta característica divide un conjunto de datos en dos subgrupos. La característica seleccionada, y el valor de corte de cada nodo se eligen para maximizar la ganancia de información entre dicho nodo y sus hijos. Específicamente, se calcula la entropía en los nodos padre e hijos, ponderada por cuantas muestras alcanzan cada uno, y se trata de maximizar la ganancia de entropía siguiendo la siguiente ecuación.
Lo bueno de esta manera de trabajar, es que podemos utilizar esta ganancia de información como un indicador de la importancia de una característica. Sin embargo, dependiendo de como construyamos un árbol, una misma característica se podría acabar usando en varios nodos. Por ello, al calcular la importancia de una característica tenemos que comprobar todos los nodos que la utilizan, y ponderar la ganancia de información en cada uno de ellos utilizando la fracción de muestras que les llegan.
Grad-CAM
El campo de la IA explicable empezó a ganar importancia, sobre todo, con la popularización de las redes convolucionales. Estas redes convolucionales son capaces de conseguir resultados espectaculares, sin embargo, parejo a esta gran capacidad llegó una mayor opacidad. Para ayudar a depurar estos modelos, nació el algoritmo Gradient-weighted Class Activation Maps (Grad-CAM).
Grad-CAM genera explicaciones visuales para cualquier red convolucional de clasificación. De manera resumida, este método sigue los siguientes pasos: 1) Encontrar la última capa convolucional del modelo a inspeccionar. 2) Pasar la imagen a inspeccionar por la red convolucional y conseguir una predicción. 3) Guardar las activaciones de la última capa convolucional. 4) Calcular los gradientes de la predicción con respecto de la última capa convolucional. 5) Promediar los gradientes para tener un solo valor para cada filtro convolucional. 6) Sumar las activaciones de la última capa convolucional ponderadas por los gradientes.
La explicación intuitiva es que la última capa convolucional debería de señalar aquellas áreas de la imagen que son importantes para calcular la salida. Además, cuando un filtro de la última capa cambia un poco, pero la salida del modelo cambia mucho, quiere decir que este filtro es importante para alcanzar dicha salida; dicho de otra manera, el gradiente de la salida con respecto de este filtro es grande. De esta manera, podemos “seleccionar” las activaciones de la última capa convolucional utilizando la información proporcionada por estos gradientes. La Figura 2 muestra un ejemplo de visualización obtenida con Grad-CAM.

LIME
Otro algoritmo popular para generar explicaciones es Local Interpretable Model-agnostic Explanations (LIME). LIME es un algoritmo agnóstico, ya que no impone restricciones específicas para explicar un modelo. Esto es diferente a Grad-CAM, que requería que el modelo tuviese una última capa convolucional justo antes de calcular las predicciones finales.
LIME trata de generar muestras aleatorias alrededor de aquella que trata de explicar, y observa las salidas del modelo para estas nuevas muestras. La parte “Local Interpretable” de LIME significa que tratará de construir un modelo interpretable, como por ejemplo un modelo de regresión lineal, usando estas muestras aleatorias locales. Por ejemplo, en el caso de imágenes, LIME empieza dividiendo la imagen de entrada en superpixels, y después genera variaciones “apagando” aleatoriamente algunos superpixels. Después, LIME construye un modelo lineal ajustando la presencia o ausencia de estos superpixels a la salida del modelo que queremos explicar y, finalmente, genera una visualización de los superpixels en base a los coeficientes del modelo lineal ajustado. La Figura 3 muestra una explicación generada con LIME.

SHAP
Si bien LIME se suele utilizar para generar explicaciones locales de muestras concretas, SHAP está enfocado a generar tanto explicaciones locales, como globales.
SHAP es un algoritmo de IA explicable inspirado por los valores Shapley, un método de teoría de juegos que trata de distribuir “pagos” entre diferentes jugadores. Estos jugadores se pueden interpretar como las características de una muestra en el conjunto de algoritmos de machine learning.
La idea general es comparar las salidas de un modelo para una determinada muestra, y la misma muestra pero con una característica “tapada”. Este procedimiento se repite para todas las combinaciones de características, para así tratar de averiguar cómo “cooperan” entre ellas. Finalmente, las contribuciones de cada característica, para todas las combinaciones, se promedian, y así conseguimos calcular la contribución de una característica específica. Este proceso se resume en la siguiente ecuación.
El problema con SHAP es que requiere muestrear todas las posibles combinaciones de características. Si un modelo opera con sólamente 4 características, SHAP solo tiene que muestrear 64 coaliciones. Sin embargo, con solamente 30 características, tendría que evaluar el modelo en millones de variaciones. Por esta razón, los autores de SHAP han creado versiones específicas como KernelSHAP o TreeSHAP que tratan de minimizar esta carga computacional.
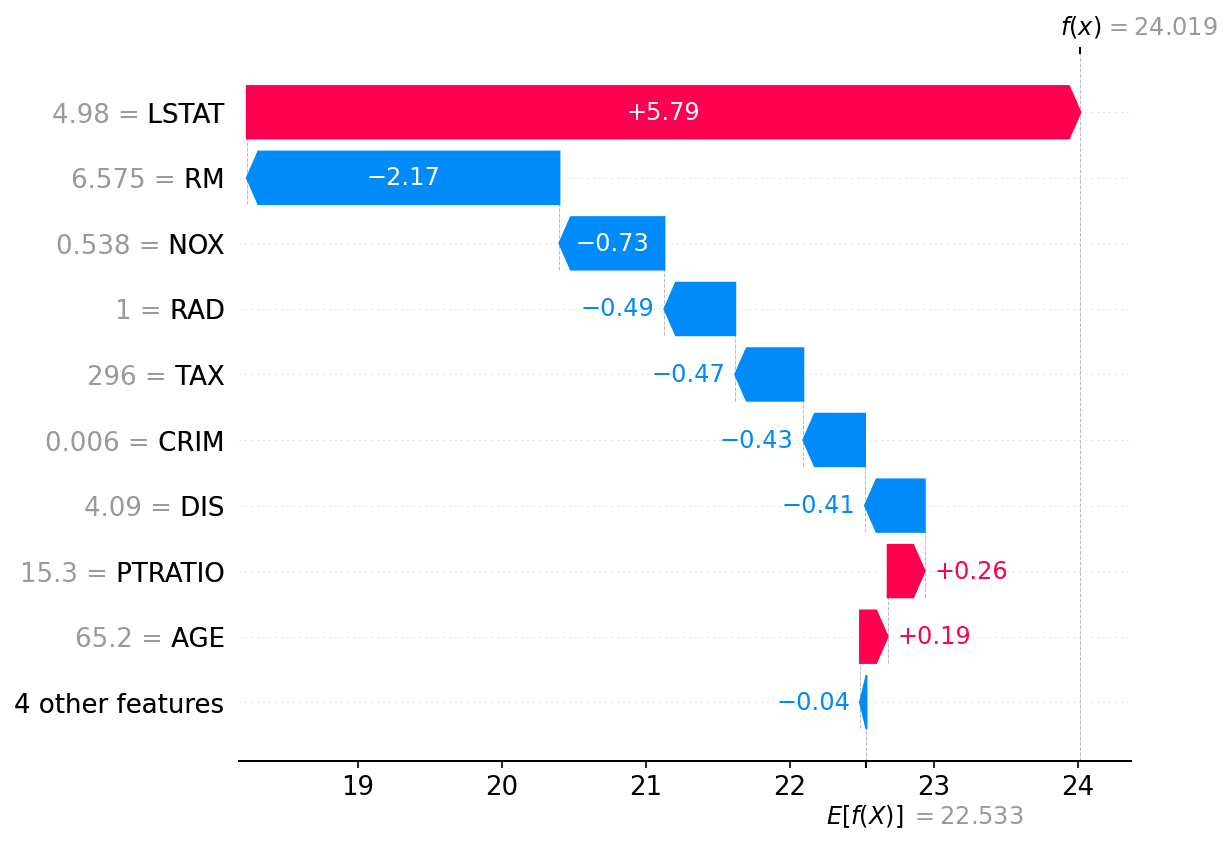
KernelSHAP es todavía una variante agnóstica, pero usa un modelo lineal para aproximar un subconjunto de coaliciones. Esto es similar al proceso que sigue LIME, sin embargo, la contribución de cada muestra se pondera de forma diferente. En LIME, el peso se calcula teniendo en cuenta la distancia entre la variante y la muestra original. Por otro lado, en SHAP, el peso se calcula en base al número de características que se han utilizado. De hecho, segun los autores de SHAP “si utilizamos el kernel Shapley que hemos propuesto como el kernel local de LIME, entonces LIME producirá estimaciones de los valores de SHAP”. La Figura 4 muestra el resultado de explicar un regresor XGBoost entrenado en el dataset Boston.
Conclusión
La IA explicable es un aspecto cada vez más crítico en el ciclo de vida del machine learning. A medida que la IA continúa penetrando en nuestras vidas, es fundamental que entendamos las decisiones tomadas por estos sistemas. Al hacer los modelos de IA más transparentes e interpretables, podemos mejorar la confianza en sus decisiones, y contribuir a que tomen decisiones justas y éticas.
En este post hemos dado un repaso a la explicabilidad e interpretabilidad en IA, introduciendo el concepto de aplicabilidad de modelos, mostrando lo amplio que es el campo de la explicabilidad, e incluyendo ejemplos concretos de técnicas populares.
A medida que el uso de la IA se vuelve más generalizado, se vuelve cada vez más claro que la explicabilidad se convertirá en un factor clave. Priorizando la explicabilidad, podemos construir sistemas inteligentes que además sean fiables.
