
¿Cómo funciona el reconocimiento facial?

El reconocimiento facial es una de esas tecnologías que llevan décadas entre nosotros, pero se han visto revolucionadas por los recientes avances en IA. Desde etiquetado automático en redes sociales, a proteger el acceso a nuestros smartphones, el reconocimiento facial está jugando un papel cada vez más importante en nuestras vidas. Sin embargo, su funcionamiento interno es todavía un misterio para muchos usuarios.
En este post, describiremos cómo funciona el reconocimiento facial, mostrando ejemplos concretos de métodos utilizados en la industria. También mencionaremos algunos problemas éticos que rodean esta tecnología, como la privacidad o el sesgo. Al concluir este post, deberías tener un buen conocimiento de qué es el reconocimiento facial, como funciona, y qué técnicas específicas se suelen utilizar en un sistema de reconocimiento facial.
Pasos típicos en un sistema de reconocimiento facial
Un sistema de reconocimiento facial utiliza algoritmos de machine learning para detectar caras y emparejarlas contra una base de datos de caras almacenadas. Dependiendo del tamaño de esta base de datos, podríamos estar hablando de verificación facial, o reconocimiento facial propiamente dicho.
La verificación facial es el proceso de comparar dos caras para tratar de averiguar si ambas muestran el mismo individuo. Este emparejamiento “uno contra uno” se suele utilizar en aplicaciones de control de acceso como Face ID. Por otro lado, el reconocimiento facial propiamente dicho trata de identificar una persona dentro de una amplia base de datos. Los sistemas de reconocimiento facial suelen ser más complejos que los de verificación, ya que incorporan sistemas de procesamiento de imagen robustos, y arquitecturas escalables. Los sistemas de reconocimiento facial pueden tener que lidiar con iluminación variable, diferentes ángulos de visión, o condiciones ambientales adversas. Además, también suelen requerir una arquitectura sofisticada que pueda encontrar individuos en bases de datos enormes.
Como muchos otros sistemas de IA, el reconocimiento facial tiene dos modalidades principales de fallo: falsos positivos, y falsos negativos. Cuando un sistema de reconocimiento facial empareja una persona con una entrada de la base de datos que no corresponde, estamos hablando de un falso positivo. Por otro lado, cuando el sistema de reconocimiento facial no es capaz de emparejar una persona en una base de datos en la que sí se encuentra, estaremos hablando de un falso negativo. Estos falsos negativos y falsos positivos normalmente se tienen que balancear, y los desarrolladores o investigadores deberán ajustar el sistema para priorizar unos u otros dependiendo de la aplicación. Por ejemplo, si estás utilizando reconocimiento facial para tratar de desbloquear tu teléfono, quizás prefieras intentarlo varias veces en vez de permitir a otro individuo no autorizado desbloquearlo; esto significa que prefieres que el sistema de reconocimiento facial tenga una tasa de falsos negativos mayor que la tasa de falsos positivos.
Por otra parte, hoy en día existen diferentes librerías de reconocimiento facial, como Deepface, que implementan un pipeline de análisis completo. Este pipeline consiste en 4 fases: Detección, alineado, representación, y verificación.
Detección de caras
La detección de caras es el primer paso de un pipeline de reconocimiento facial. Consiste en identificar la presencia de caras en una imagen y localizarlas, normalmente enmarcándolas en un recuadro. Este proceso normalmente utiliza algoritmos de machine learning que estudian características como el color, textura, o forma, utilizando un conjunto de bloques de análisis aprendidos mediante un conjunto de datos de entrenamiento.
Una de las familias populares de algoritmos de detección de caras son las redes convolucionales “single stage”. Estas redes analizan la imagen en una sola pasada, sin necesitar pasos intermedios como pueden ser la propuesta de regiones, alcanzando así altas velocidades de detección. Algunas arquitecturas populares de esta familia son RetinaFace, SSD, o YOLO. La Figura 1 muestra el resultado de aplicar RetinaFace para detectar caras.

Alineado de caras
Una vez detectada, la cara podría estar rotada, lo que reduce el rendimiento del reconocimiento facial. Para alcanzar el mayor rendimiento posible, se introduce un paso en el proceso para tratar de enderezar la cara. Este paso para enderezar la cara suele consistir en localizar puntos faciales como ojos, nariz, o boca, y entonces transformar la imagen de la cara para que la posición de estos puntos sea estándar.
Algunos algoritmos de detección de caras, como por ejemplo RetinaFace, ya detectan estos puntos faciales. En concreto, RetinaFace detecta ambos ojos, la nariz, y las comisuras de los labios. Una vez detectados estos puntos, podemos rotar la imagen para que ambos ojos queden a la misma altura. Por otro lado, otros algoritmos de detección no identifican estos puntos faciales. En este caso los desarrolladores pueden introducir un paso de postproceso que use redes sencillas como MobileNet para regresar estos puntos.
Representación de caras
Los sistemas de reconocimiento facial no suelen utilizar la imagen de la cara directamente, lo que suelen hacer es calcular primero una firma digital. Esta firma es simplemente una lista pequeña de números que resume la apariencia de la cara. Los sistemas de reconocimiento facial almacenan estas firmas, también llamados vectores de características, en bases de datos que más tarde podrán ser consultadas para emparejar nuevas caras.
Algunas técnicas tradicionales como Local Binary Pattern Histograms (LBPH), usan técnicas sencillas como umbralizado e histogramas para representar la cara. Sin embargo, la mejora que han sufrido los algoritmos de deep learning ha llevado a esos métodos tradicionales a ser cada vez menos utilizados. Hoy en día, los sistemas de reconocimiento facial pueden utilizar redes convolucionales como Resnet, o transformers de visión como ViT, entrenados con funciones basadas en softmax como ArcFace.
Verificación facial
Una vez calculado el vector de características de una cara, un último paso de verificación trata de encontrar la entrada más parecida en la base de datos y confirma que son suficientemente parecidos. De manera tradicional, esto se consigue calculando una métrica de distancia entre el vector objetivo y cada entrada de la base de datos. Sin embargo, si hiciésemos esto para todas las entradas conllevaría un coste computacional muy elevado, por lo que otros métodos como Approximate Nearest Neighbors (ANN) se suelen utilizar cuando tratamos con bases de datos de tamaño considerable.
Independientemente del método de búsqueda utilizado, la métrica de distancia siempre se suele utilizar para comparar la cara objetivo y la entrada de la base de datos. Existen diferentes métricas como la distancia euclídea, la distancia coseno, o la distancia de Mahalanobis. Por ejemplo, la distancia euclídea calcula la distancia entre dos vectores de características como la raíz cuadrada de la suma de las diferencias cuadradas de sus elementos.
Algoritmos de reconocimiento facial populares
Hasta ahora hemos visto algunos de los pasos más típicos en un pipeline de reconocimiento facial. Desde el método Haar cascades, hasta redes de aprendizaje profundo, el reconocimiento facial se puede implementar con una variedad de algoritmos. En esta sección veremos dos algoritmos populares dentro de un pipeline de reconocimiento facial: RetinaFace y ArcFace. Estos algoritmos utilizan el poder de las redes de aprendizaje profundo para detectar y reconocer caras con gran precisión, posibilitando el despliegue de sistemas de reconocimiento facial en escenarios realistas como el control de acceso.
RetinaFace
RetinaFace es un algoritmo de detección de caras que utiliza una arquitectura convolucional para localizar caras en imágenes. Las características principales de RetinaFace son: 1) Sigue una arquitectura “single stage”. 2) Calcula información multiescala con una “feature pyramid network”. 3) Incorpora un módulo de contexto para agrandar el campo receptivo utilizado para detectar caras. 4) Aprende varias tareas al mismo tiempo para mejorar su rendimiento. La Figura 2 muestra la arquitectura de RetinaFace.
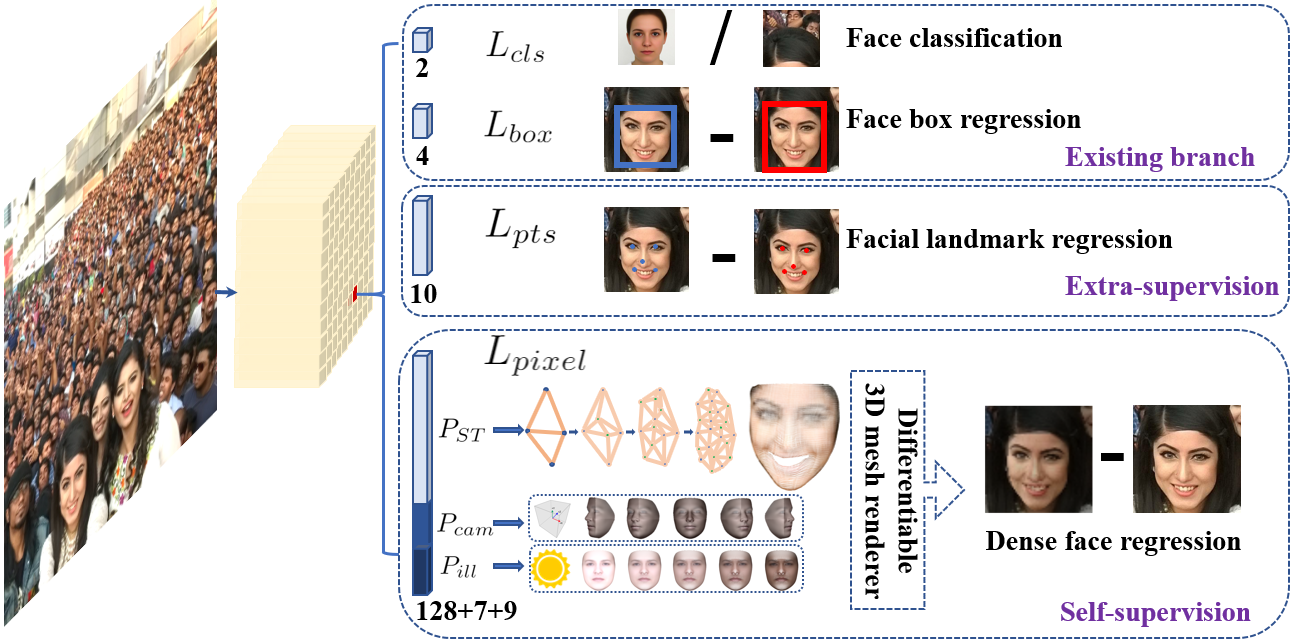
Una cualidad deseable en todo detector de caras es la velocidad de cálculo. Para maximizar esta velocidad, RetinaFace sigue una arquitectura “single stage”. Al contrario de las redes que utilizan procesos de proposición de regiones, RetinaFace extrae información directamente de las capas intermedias de una red de clasificación como ResNet. Esta información se utiliza para calcular los recuadros que enmarcan las caras directamente con capas convolucionales.
Otra característica clave de RetinaFace es el uso de una pirámide de características “feature pyramid network” para extraer información multiescala. La detección de caras en diferentes escalas es una cualidad deseable de cualquier detector, sin embargo, en vez de crear una pirámide de imágenes y ejecutar el detector en cada imágen de la pirámide, RetinaFace construye una pirámide interna de características. Esta pirámide de características mejora el balance entre escala e información semántica al incorporar información visual a cada capa intermedia de la red convolucional.
Además, para maximizar su robustez, RetinaFace incluye un módulo de contexto que agranda el campo receptivo que se usa para realizar la detección. Al ejecutar varias convoluciones de manera secuencial antes de hacer la detección final, RetinaNet aumenta el campo receptivo que le llega al módulo que realiza esta detección final.
Finalmente, RetinaFace también utiliza aprendizaje multiobjetivo para mejorar el rendimiento de la detección de caras. En vez de simplemente detectar los reduadros de las caras, RetinaNet tiene cuatro salidas diferentes. Las dos salidas principales son los resucadros de las caras, y la puntuación de esas caras. Sin embargo, RetinaFace también localiza 5 puntos faciales, y trata de recrear la apariencia de la cara localizada. De esta manera, consigue aprender una representación interna robusta que engloba cada uno de los diferentes objetivos, y así consigue mejorar el rendimiento de la detección. Además, los puntos faciales también se podrán utilizar para alinear las caras y mejorar así el rendimiento global del proceso de reconocimiento facial.
ArcFace
ArcFace es un algoritmo de reconocimiento facial que utiliza redes convolucionales para generar vectores altamente discriminativos. Específicamente, ArcFace es una función de coste creada para mejorar el rendimiento de algoritmos de verificación facial, tratando de mejorar la distancia que separa descriptores de diferentes caras. La idea principal consiste en entrenar una red de clasificación, como ResNet, para clasificar la identidad de cada cara y además tener un margen que separe cada representación.
La función de coste ArcFace se basa en softmax, que es una de las funciones de coste más populares en deep learning, especialmente en tareas de clasificación. Sin embargo, al contrario que softmax, Arcface impone un margen angular entre las características de diferentes clases.
Esto se consigue modificando la ecuación típica de sofmax. Softmax recive el resultado de multiplicar cada peso y características intermedias. En vez de simplemente aplicar esta multiplicación, el producto se reescribe como la magnitud de ambos vectores multiplicado por su coseno. De esta manera, si añadimos un margen al ángulo con respecto a la clase objetivo, podemos forzar a que las características de dicha clase estén separadas del resto. La Figura 3 muestra cómo diferentes funciones de coste imponen diferentes márgenes.
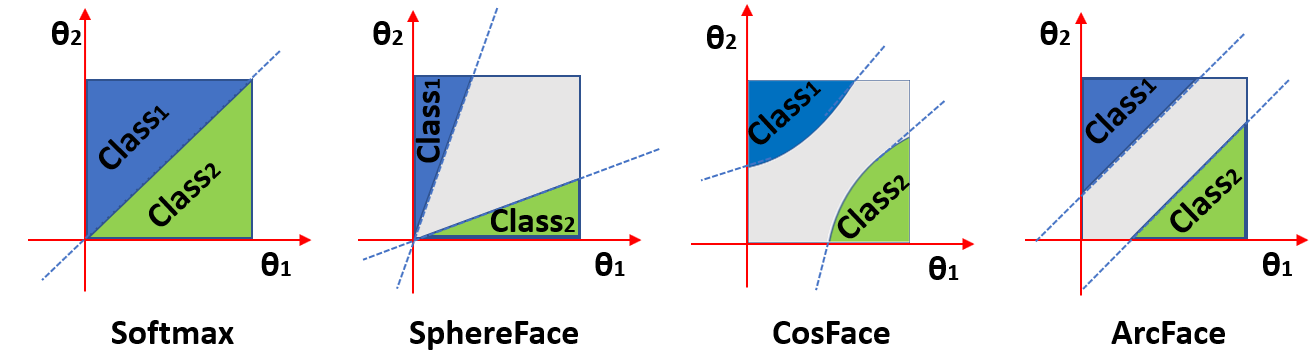
Al introducir este margen angular, la función de coste ArcFace está tratando de agrupar los vectores pertenecientes a la misma clase, y separar aquellos que pertenecen a clases diferentes, resultando en un espació de características más discriminativo que ayuda a realizar reconocimiento facial. Además, el margen se puede ajustar para controlar el grado de separación, permitiendo que la red se adapte a diferentes dificultades.
Reconocimiento facial a escala
Hasta ahora hemos descrito un pipeline de reconocimiento facial utilizando RetinaFace para detectar caras y alinearlas, y un clasificador convolucional entrenado con ArcFace para representarlas. Sin embargo, a medida que los sistemas de reconocimiento facial se popularizan, la necesidad de hacerlos escalables se vuelve más importante. Diseñar un sistema de reconocimiento facial que opere en entornos reales requiere algo más que simplemente desplegar un par de redes convolucionales, necesitamos también optimizar requisitos específicos como la latencia, el tiempo de procesamiento, o la memoria utilizada. En esta sección analizaremos algunos de los factores clave a la hora de escalar aplicaciones de reconocimiento facial. Primero trataremos la ejecución de algoritmos de detección de caras en tiempo real. Después mostraremos algunas estrategias para tratar entornos que tienen millones de identidades.
Lo primero es lo primero, cómo podemos escalar las fases de detección y representación? Pues en este caso la complicación principal es la velocidad de procesamiento, así que podemos utilizar tecnologías de clusters como Kubernetes, Ray, o el autoescalado de un cloud público para escalar horizontalmente la aplicación. Frameworks como Kubernetes han ganado una grán popularidad a la hora de hacer despliegues escalables, disponibles, y portables a diferentes infraestructuras. Sin embargo, si bien es cierto que Kubernetes es una herramienta muy potente, también es verdad que consume muchos recursos y es difícil de configurar y mantener. Por otro lado, frameworks como Ray se han diseñado específicamente para simplificar el escalado de aplicaciones con machine learning. Para crear un cluster con Ray solo tenemos que crear un archivo YAML de 50-100 líneas con la descripción de nuestros trabajadores. Ray no necesita que definas de manera explícita “deployments”, “services” o “configmaps” como en Kubernetes, solo tienes que definir tus trabajadores y ya está. Además, podemos decorar el código de inferencia con
@serve.deployment(ray_actor_options={"num_cpus": 0.2, "num_gpus": 0})
para desplegarlo en un cluster de Ray que hayamos definido. Las opciones min_workers y max_workers, así como los requisitos que pongas en las funciones desplegadas, determinarán como escala el cluster; no tienes que definir estrategias en base a pods y clusters como en Kubernetes.
Otro factor clave a la hora de escalar sistemas de reconocimiento facial es cómo manejar el almacenamiento, recuperación, y emparejado de firmas faciales. Cuando una aplicación trata con millones de identidades, esto se convierte en un problema importante, ya que simplemente almacenar cada firma firma en memoria, e ir una a una calculando la distancia, se vuelve demasiado costoso. Por suerte, podemos utilizar motores de búsqueda como Elasticsearch para realizar esta búsqueda de manera eficiente. Esta manera de trabajar tiene dos variantes: 1) Dejar que Elasticsearch calcule la distancia utilizando script queries. 2) Utilizar búsqueda KNN para obtener un resultado aproximado. Cuando la base de datos es suficientemente larga, la búsqueda aproximada nos permite seguir ejecutando búsquedas eficientemente. Sin embargo, los resultados de esta búsqueda aproximada pueden contener errores, lo cual convierte el uso de esta técnica en un balance entre velocidad y precisión.
Conclusión
El reconocimiento facial es una tecnología compleja que encapsula algoritmos de detección, alineado, representación, y emparejado. En este post hemos descrito estos pasos típicos de un pipeline de reconocimiento facial, y también hemos explicado algunos de los algoritmos más populares. Concluyendo este artículo en tecnología de reconocimiento facial, está claro que la tecnología tiene el potencial de volverse un pilar fundamental de nuestras vidas. Además, recientes avances en machine learning han posibilitado reconocer caras con rendimiento casi humano. Por otra parte, el escalado de estos procesos se ha democratizado con herramientas que nos permiten realizar despliegues a escalas masivas.
Por último, el futuro de las tecnologías de reconocimiento facial dependerá de cómo se desarrolle e implemente. No solo será importante empujar la precisión y velocidad de estos sistemas, sinó que también habrá que mantener presentes las cuestiones éticas, y así aprovechar el potencial de esta tecnología para crear un mundo mejor para todos.
